
Section 4 Exploratory Network Analysis

Exploratory network analysis is simply exploratory data analysis applied to network data. This covers a range of statistical and visual techniques designed to explore the structure of networks as well as the relative positions of nodes and edges. These methods can be used to look for particular structures or patterning of interest, such as the most central nodes, or to summarize and describe the structure of the network to paint a general picture of it before further analysis. This section serves as a companion to Chapter 4 in the Brughmans and Peeples book (2023) and provides basic examples of the exploratory network analysis methods outlined in the book as well as a few others.
Note that we have created a distinct section on exponential random graph models (ERGM) in the “Going Beyond the Book” section of this document as that approach necessitates extended discussion. We replicate the boxed example from Chapter 4 of the book in that section.
4.1 Example Network Objects
In order to facilitate the exploratory analysis examples in this section, we want to first create a set of igraph and statnet network objects that will serve our purposes across all of the analyses below. Specifically, we will generate and define:
-
simple_net- A simple undirected binary network with isolates -
simple_net_noiso- A simple undirected binary network without isolates -
directed_net- A directed binary network -
weighted_net- An undirected weighted network -
sim_net_i- A similarity network with edges weighted by similarity in theigraphformat -
sim_net- A similarity network with edges weighted by similarity in thenetworkformat -
sim_mat- A data frame object containing a weighted similarity matrix
Each of these will be used as appropriate to illustrate particular methods.
In the following chunk of code we initialize all of the packages that we will use in this section and define all of the network objects that we will use (using the object names above). In these examples we will once again use the Cibola technological similarity data we used in the Network Data Formats section previously.
# initialize packages
library(igraph)
library(statnet)
library(intergraph)
library(vegan)
# read in csv data
cibola_edgelist <-
read.csv(file = "data/Cibola_edgelist.csv", header = TRUE)
cibola_adj_mat <- read.csv(file = "data/Cibola_adj.csv",
header = T,
row.names = 1)
# Simple network with isolates
simple_net <-
igraph::graph_from_adjacency_matrix(as.matrix(cibola_adj_mat),
mode = "undirected")
# Simple network with no isolates
simple_net_noiso <-
igraph::graph_from_edgelist(as.matrix(cibola_edgelist),
directed = FALSE)
#Create a directed network by sub-sampling edge list
set.seed(45325)
el2 <- cibola_edgelist[sample(seq(1, nrow(cibola_edgelist)), 125,
replace = FALSE), ]
directed_net <- igraph::graph_from_edgelist(as.matrix(el2),
directed = TRUE)
# Create a weighted undirected network by adding column of random
# weights to edge list
cibola_edgelist$weight <- sample(seq(1, 4), nrow(cibola_edgelist),
replace = TRUE)
weighted_net <-
igraph::graph_from_edgelist(as.matrix(cibola_edgelist[, 1:2]),
directed = FALSE)
E(weighted_net)$weight <- cibola_edgelist$weight
# Create a similarity network using the Brainerd-Robinson metric
cibola_clust <-
read.csv(file = "data/Cibola_clust.csv",
header = TRUE,
row.names = 1)
clust_p <- prop.table(as.matrix(cibola_clust), margin = 1)
sim_mat <-
(2 - as.matrix(vegan::vegdist(clust_p, method = "manhattan"))) / 2
sim_net <- network(
sim_mat,
directed = FALSE,
ignore.eval = FALSE,
names.eval = "weight"
)
sim_net_i <- asIgraph(sim_net)4.2 Calculating Network Metrics in R
Although the calculations behind the scenes for centrality metrics, clustering algorithms, and other network measures may be somewhat complicated, calculating these measures in R using network objects is usually quite straight forward and typically only involves a single function and a couple of arguments within it. There are, however, some things that need to be kept in mind when applying these methods to network data. In this document, we provide examples of some of the most common functions you may use as well as a few caveats and potential problems.
Certain network metrics require networks with specific properties and may produce unexpected results if the wrong kind of network is used. For example, closeness centrality is only well defined for binary networks that have no isolates. If you were to use the igraph::closeness command to calculate closeness centrality on a network with isolates, you would get results, but you would also get a warning telling you “closeness centrality is not well-defined for disconnected graphs.” For other functions if you provide data that does not meet the criteria required by that function you may instead get an error and have no results returned. In some cases, however, a function may simply return results and not provide any warning, so it is important that you are careful when selecting methods to avoid providing data that violates assumptions of the method provided. Remember, if you have questions about how a function works or what it requires you can type ?function_name at the console with the function in question and you will get the help document that should provide more information. You can also include package names in the help call to ensure you get the correct function (i.e., ?igraph::degree)
4.3 Centrality
One of the most common kinds of exploratory network analysis involves calculating basic network centrality and centralization statistics. There are a wide array of methods available in R through the igraph and statnet packages. In this section we highlight a few examples as well as a few caveats to keep in mind.
4.3.1 Degree Centrality
Degree centrality can be calculated using the igraph::degree function for simple networks with or without isolates as well as simple directed networks. This method is not, however, appropriate for weighted networks or similarity networks (because it expects binary values). If you apply the igraph::degree function to a weighted network object you will simply get the binary network degree centrality values. The alternative for calculating weighted degree for weighted and similarity networks is to simply calculate the row sums of the underlying similarity matrix (minus 1 to account for self loops) or adjacency matrix. For the degree function the returned output is a vector of values representing degree centrality which can further be assigned to an R object, plotted, or otherwise used. We provide a few examples here to illustrate. Note that for directed graphs you can also specify the mode as in for in-degree or out for out-degree or all for the sum of both.
Graph level degree centralization is equally simple to call using the centr_degree function. This function returns an object with multiple parts including a vector of degree centrality scores, the graph level centralization metric, and the theoretical maximum number of edges (n * [n-1]). This metric can be normalized such that the maximum centralization value would be 1 using the normalize = TRUE argument as we demonstrate below. See the comments in the code chunk below to follow along with which type of network object is used in each call. In most cases we only display the first 5 values to prevent long lists of output (using the [1:5] command).
# simple network with isolates
igraph::degree(simple_net)[1:5]## Apache.Creek Atsinna Baca.Pueblo Casa.Malpais Cienega
## 11 8 1 11 13
# simple network no isolates
igraph::degree(simple_net_noiso)[1:5]## Apache Creek Casa Malpais Coyote Creek Hooper Ranch Horse Camp Mill
## 11 11 11 11 12
# directed network
igraph::degree(directed_net, mode = "in")[1:5] # in-degree## Coyote Creek Techado Springs Hubble Corner Tri-R Pueblo Heshotauthla
## 1 6 5 6 2
igraph::degree(directed_net, mode = "out")[1:5] # out-degree## Coyote Creek Techado Springs Hubble Corner Tri-R Pueblo Heshotauthla
## 6 2 5 2 11
# weighted network - rowSums of adjacency matrix
(rowSums(as.matrix(
as_adjacency_matrix(weighted_net,
attr = "weight")
)) - 1)[1:5]## Apache Creek Casa Malpais Coyote Creek Hooper Ranch Horse Camp Mill
## 25 29 21 18 27
# similarity network. Note we use the similarity matrix here and
# not the network object
(rowSums(sim_mat) - 1)[1:5]## Apache Creek Atsinna Baca Pueblo Casa Malpais Cienega
## 16.00848 15.87024 14.77997 17.30358 17.09394
# If you want to normalize your degree centrality metric by the
# number of nodes present you can do that by adding the normalize=TRUE
# command to the function calls above. For weighted and similarity
# networks you can simply divide by the number of nodes minus 1.
igraph::degree(simple_net, normalize = T)[1:5]## Apache.Creek Atsinna Baca.Pueblo Casa.Malpais Cienega
## 0.36666667 0.26666667 0.03333333 0.36666667 0.43333333
# it is also possible to directly plot the degree distribution for
# a given network using the degree.distribution function.
# Here we embed that call directly in a call for a histogram plot
# using the "hist" function
hist(igraph::degree.distribution(simple_net))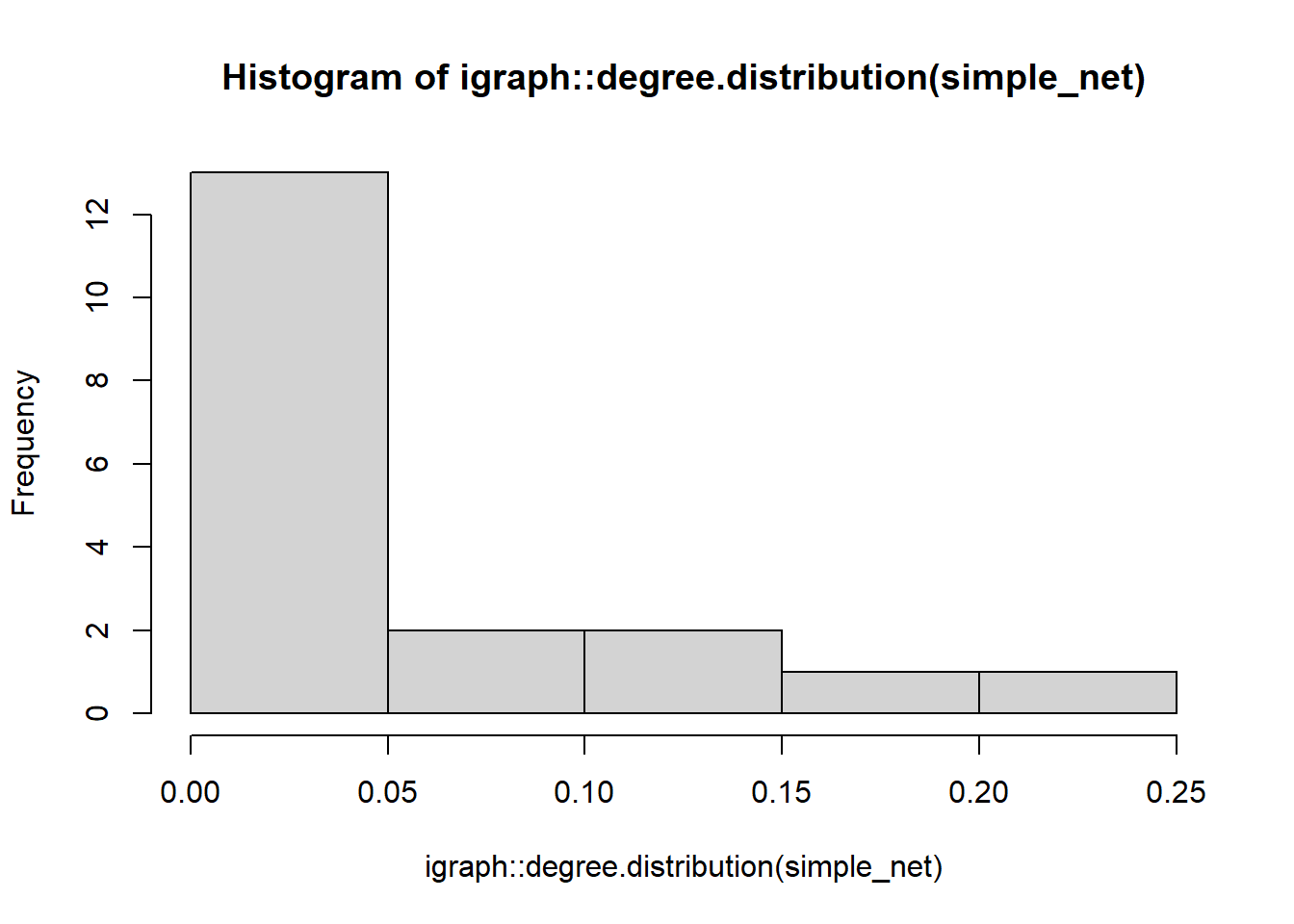
# graph level centralization
igraph::centr_degree(simple_net)## $res
## [1] 11 8 1 11 13 11 6 13 14 18 11 12 13 11 12 12 13 14 11 5 10 12 13 13 9
## [26] 14 13 14 6 0 10
##
## $centralization
## [1] 0.2408602
##
## $theoretical_max
## [1] 930
# To calculate centralization score for a similarity matrix, use the
# sna::centralization function
sna::centralization(sim_mat, normalize = TRUE, sna::degree)## [1] 0.1082207If you are interested in calculating graph level density you can do this using the edge_density function. Note that just like the degree function above, this only works for binary networks and if you submit a weighted network object you will simply get the binary edge density value.
edge_density(simple_net_noiso)## [1] 0.383908
edge_density(weighted_net)## [1] 0.3839084.3.2 Betweenness Centrality
The betweenness functions work very much like the degree function calls above. Betweenness centrality in igraph can be calculated for simple networks with and without isolates, directed networks, and weighted networks. In the case of weighted networks or similarity networks, the shortest paths between sets of nodes are calculated such that the path of greatest weight is taken at each juncture. You can normalize your results by using normalize = TRUE just like you could for degree. The igraph::betweenness function will automatically detect if a graph is directed or weighted and use the appropriate method but you can also specify a particular edge attribute to use for weight if you perhaps have more than one weighting scheme.
# calculate betweenness for simple network
igraph::betweenness(simple_net)[1:5]## Apache.Creek Atsinna Baca.Pueblo Casa.Malpais Cienega
## 1.125000 0.000000 0.000000 8.825306 8.032865
# calculate betweenness for weighted network
igraph::betweenness(weighted_net, directed = FALSE)[1:5]## Apache Creek Casa Malpais Coyote Creek Hooper Ranch Horse Camp Mill
## 20.94423 18.96259 17.67829 15.66853 2.78036
# calculate betweenness for weighted network specifying weight attribute
igraph::betweenness(weighted_net, weights = E(weighted_net)$weight)[1:5]## Apache Creek Casa Malpais Coyote Creek Hooper Ranch Horse Camp Mill
## 20.94423 18.96259 17.67829 15.66853 2.78036
# calculate graph level centralization
centr_betw(simple_net)## $res
## [1] 1.1250000 0.0000000 0.0000000 8.8253059 8.0328650 3.2862641
## [7] 0.2500000 58.7048084 15.6031093 142.3305364 1.1250000 9.0503059
## [13] 11.9501530 6.2604913 1.2590038 12.8566507 8.0328650 41.0052110
## [19] 0.5722222 2.7950980 0.2844828 9.0503059 15.3558646 8.0328650
## [25] 0.0000000 16.0653473 11.9501530 17.0225282 0.0000000 0.0000000
## [31] 2.1735632
##
## $centralization
## [1] 0.3064557
##
## $theoretical_max
## [1] 130504.3.3 Eigenvector Centrality
The igraph::eigen_centrality function can be calculated for simple networks with and without isolates, directed networks, and weighted networks. By default scores are scaled such that the maximum score of 1. You can turn this scaling of by using the scale = FALSE argument. This function automatically detects whether a network object is directed or weighted but you can also call edge attributes to specify a particular weight attribute. By default this function outputs many other features of the analysis such as the number of steps toward convergence and the number of iterations but if you just want the centrality results you can use the atomic vector call to $vector.
eigen_centrality(simple_net,
scale = TRUE)$vector[1:5]## Apache.Creek Atsinna Baca.Pueblo Casa.Malpais Cienega
## 0.46230981 0.54637071 0.07114132 0.53026366 0.85007181
eigen_centrality(
weighted_net,
weights = E(weighted_net)$weight,
directed = FALSE,
scale = FALSE
)$vector[1:5]## Apache Creek Casa Malpais Coyote Creek Hooper Ranch Horse Camp Mill
## 0.08116512 0.10608344 0.07254989 0.05355994 0.101235954.3.4 Page Rank Centrality
The igraph::page_rank function can be calculated for simple networks with and without isolates, directed networks, and weighted networks. By default scores are scaled such that the maximum score is 1. You can turn this scaling off by using the scale = FALSE argument. This function automatically detects whether a network object is directed or weighted but you can also call edge attributes to specify a particular weight attribute. You can change the algorithm used to implement the page rank algorithm (see help for details) and can also change the damping factor if desired.
page_rank(directed_net,
directed = TRUE)$vector[1:5]## Coyote Creek Techado Springs Hubble Corner Tri-R Pueblo Heshotauthla
## 0.01375364 0.03433734 0.02521968 0.04722743 0.01549665
page_rank(
weighted_net,
weights = E(weighted_net)$weight,
directed = FALSE,
algo = "prpack"
)$vector[1:5]## Apache Creek Casa Malpais Coyote Creek Hooper Ranch Horse Camp Mill
## 0.03340837 0.03761940 0.02901255 0.02610001 0.035514774.3.5 Closeness Centrality
The igraph::closeness function calculates closeness centrality and can be calculated for directed and undirected simple or weighted networks with no isolates. This function can also be used for networks with isolates, but you may receive an additional message suggesting that closeness is undefined for networks that are not fully connected. For very large networks you can use the igraph::estimate_closeness function with a cutoff setting that will consider paths of length up to cutoff to calculate closeness scores. For directed networks you can also specify whether connections in, out, or in both directions should be used.
Note that the function igraph::closeness() should not
normally be used with networks with multiple components. Depending on
your settings, however, the function call may not return an error so be
careful.
Let’s take a look at some examples:
igraph::closeness(simple_net)[1:5]## Apache.Creek Atsinna Baca.Pueblo Casa.Malpais Cienega
## 0.01470588 0.01470588 0.01315789 0.01886792 0.02000000
igraph::closeness(simple_net_noiso)[1:5]## Apache Creek Casa Malpais Coyote Creek Hooper Ranch Horse Camp Mill
## 0.01470588 0.01886792 0.01754386 0.01470588 0.01923077## Apache Creek Casa Malpais Coyote Creek Hooper Ranch Horse Camp Mill
## 0.01010101 0.01298701 0.01219512 0.01111111 0.01063830
igraph::closeness(directed_net, mode = "in")[1:5]## Coyote Creek Techado Springs Hubble Corner Tri-R Pueblo Heshotauthla
## 1.00000000 0.04166667 0.04761905 0.04347826 0.090909094.3.6 Hubs and Authorities
In directed networks it is possible to calculate hub and authority scores to identify nodes that are characterized by high in-degree and high out-degree in particular. Because this is a measure that depends on direction it is only appropriate for directed network objects. If you run this function for an undirected network hub scores and authority scores will be identical. These functions can also be applied networks that are both directed and weighted. If you do not want all options printed you can use the atomic vector $vector call as well.
igraph::hub_score(directed_net)$vector[1:5]## Coyote Creek Techado Springs Hubble Corner Tri-R Pueblo Heshotauthla
## 0.31998744 0.12265832 0.30740409 0.08450797 1.00000000
igraph::authority_score(directed_net)$vector[1:5]## Coyote Creek Techado Springs Hubble Corner Tri-R Pueblo Heshotauthla
## 0.05372558 0.32708203 0.28835263 0.35970234 0.252652874.4 Triads and clustering
Another important topic in network science concerns considerations of the overall structure and clustering of connections across a network as a whole. There are a variety of methods which have been developed to characterize the overall degree of clustering and closure in networks, many of which are based on counting triads of various configurations. In this section, we briefly outline approaches toward evaluating triads, transitivity, and clustering in R.
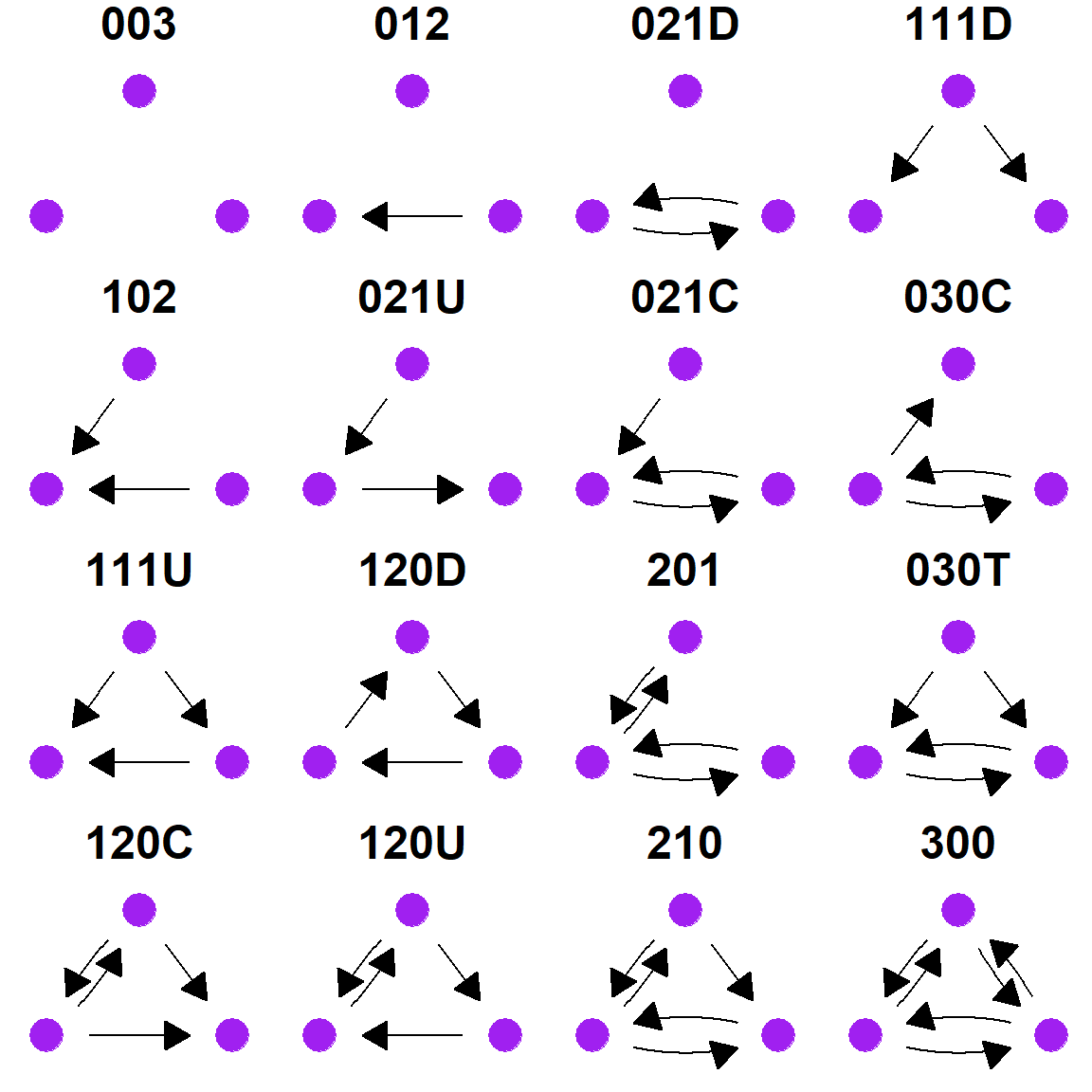
4.4.1 Triads
A triad is simply a set of three nodes and a description of the configuration of edges among them. For undirected graphs, there are four possibilities for describing the connections among those nodes (empty graph, 1 connection, 2 connections, 3 connections). For directed graphs the situation is considerably more complicated because ties can be considered in both directions and an edge in one direction isn’t necessarily reciprocated. Thus there are 16 different configurations that can exist (see Brughmans and Peeples 2023: Figure 4.4).
One common method for outlining the overall structural properties of a network is to conduct a “triad census” which counts each of the 4 or 16 possible triads for a given network. Although a triad census can be conducted on an undirected network using the igraph::triad_census function, a warning will be returned along with 0 results for all impossible triad configurations so be aware. The results are returned as a vector of counts of each possible node configuration in an order outlined in the help document associated with the function (see ?triad_census for more).
igraph::triad_census(directed_net)## [1] 1404 2007 0 134 146 174 0 0 195 0 0 0 0 0 0
## [16] 0
igraph::triad_census(simple_net)## Warning in igraph::triad_census(simple_net): At
## vendor/cigraph/src/misc/motifs.c:1140 : Triad census called on an undirected
## graph. All connections will be treated as mutual.## [1] 1033 0 2551 0 0 0 0 0 0 0 441 0 0 0 0
## [16] 470Often can be useful to visualize the motifs defined for each entry in the triad census and this can be done using the graph_from_isomorphism_class() function which outputs every possible combination of nodes of a given size you specify (3 in this case). We can plot these configurations in a single plot using the ggraph and ggpubr packages. These packages are described in more detail in the visualization section of this document. We label each configuration using the “isomporhism code” that are frequently used to describe triads.
library(ggraph)
library(ggpubr)
g <- list()
xy <-
as.data.frame(matrix(
c(0.1, 0.1, 0.9, 0.1, 0.5, 0.45),
nrow = 3,
ncol = 2,
byrow = TRUE
))
names <- c("003", "012", "102", "021D", "021U", "021C",
"111D", "111U", "030T", "030C", "201", "120D",
"120U", "120C", "210", "300")
for (i in 0:15) {
g_temp <- graph_from_isomorphism_class(size = 3,
number = i,
directed = TRUE)
g[[i + 1]] <- ggraph(g_temp,
layout = "manual",
x = xy[, 1],
y = xy[, 2]) +
xlim(0, 1) +
ylim(0, 0.5) +
geom_node_point(size = 6, col = "purple") +
geom_edge_fan(
arrow = arrow(length = unit(4, "mm"),
type = "closed"),
end_cap = circle(6, "mm"),
start_cap = circle(6, "mm"),
edge_colour = "black"
) +
theme_graph(
plot_margin =
margin(2, 2, 2, 2)
) +
ggtitle(names[i + 1]) +
theme(plot.title = element_text(hjust = 0.5))
}
# motifs ordered by order in triad_census function
ggarrange(
g[[1]], g[[2]], g[[4]], g[[7]],
g[[3]], g[[5]], g[[6]], g[[10]],
g[[8]], g[[12]], g[[11]], g[[9]],
g[[14]], g[[13]], g[[15]], g[[16]],
nrow = 4,
ncol = 4
)
4.4.2 Transitivity and Clustering
A network’s global average transitivity (or clustering coefficient) is three times the number of closed triads over the total number of triads in a network. This measure can be calculated using igraph::transitivity for simple networks with or without isolates, directed networks, and weighted networks. There are options within the function to determine the specific type of transitivity (global transitivity is the default) and for how to treat isolates. See the help document (?igraph::transitivity) for more details. If you want to calculate local transitivity for a particular node you can use the type = "local" argument. This will return a NA value for nodes that are not part of any triads (isolates and nodes with a single connection).
igraph::transitivity(simple_net, type = "global")## [1] 0.7617504
igraph::transitivity(simple_net, type = "local")## Apache.Creek Atsinna Baca.Pueblo
## 0.8727273 1.0000000 NaN
## Casa.Malpais Cienega Coyote.Creek
## 0.8363636 0.8333333 0.8727273
## Foote.Canyon Garcia.Ranch Heshotauthla
## 0.8666667 0.4358974 0.7252747
## Hinkson Hooper.Ranch Horse.Camp.Mill
## 0.4183007 0.8727273 0.8333333
## Hubble.Corner Jarlosa Los.Gigantes
## 0.7435897 0.8000000 0.8787879
## Mineral.Creek.Pueblo Mirabal Ojo.Bonito
## 0.7272727 0.8333333 0.6703297
## Pescado.Cluster Platt.Ranch Pueblo.de.los.Muertos
## 0.9272727 0.7000000 0.9555556
## Rudd.Creek.Ruin Scribe.S Spier.170
## 0.8333333 0.7692308 0.8333333
## Techado.Springs Tinaja Tri.R.Pueblo
## 1.0000000 0.7582418 0.7435897
## UG481 UG494 WS.Ranch
## 0.7142857 1.0000000 NaN
## Yellowhouse
## 0.82222224.5 Walks, Paths, and Distance
There are a variety of network metrics which rely on distance and paths across networks that can be calculated in R. There are a great many functions available and we highlight just a few here.
4.5.1 Distance
In some cases, you may simply want information about the graph distance between nodes in general or perhaps the average distance. There are a variety of functions that can help with this including igraph::distances and igraph::mean_distance. These work on simple networks, directed networks, and weighted networks.
# Create matrix of all distances among nodes and view the first
# few rows and columns
igraph::distances(simple_net)[1:4, 1:4]## Apache.Creek Atsinna Baca.Pueblo Casa.Malpais
## Apache.Creek 0 4 4 1
## Atsinna 4 0 2 3
## Baca.Pueblo 4 2 0 3
## Casa.Malpais 1 3 3 0
# Calculate the mean distance for a network
igraph::mean_distance(simple_net)## [1] 1.9494254.5.2 Shortest Paths
If you want to identify particular shortest paths to or from nodes in a network you can use the igraph::shortest_paths function or alternatively the igraph::all_shortest_paths if you want all shortest paths originating at a particular node. To call this function you simply need to provide a network object and an id for the origin and destination of the path. The simplest solution is just to call the node number. This function works with directed and undirected networks with or without weights. Although it can be applied to networks with isolates, the isolates themselves will produce NA results.
# track shortest path from Apache Creek to Pueblo de los Muertos
igraph::shortest_paths(simple_net, from = 1, to = 21)## $vpath
## $vpath[[1]]
## + 5/31 vertices, named, from edc90a4:
## [1] Apache.Creek Casa.Malpais Garcia.Ranch
## [4] Heshotauthla Pueblo.de.los.Muertos
##
##
## $epath
## NULL
##
## $predecessors
## NULL
##
## $inbound_edges
## NULLThe output provides the ids for all nodes crossed in the path from origin to destination.
4.5.3 Diameter
The igraph::diameter function calculates the diameter of a network (the longest shortest path) and you can also use the farthest_vertices function to get the ids of the nodes that form the ends of that longest shortest path. This metric can be calculated for directed and undirected, weighted and unweighted networks, with or without isolates.
igraph::diameter(directed_net, directed = TRUE)## [1] 4
igraph::farthest_vertices(directed_net, directed = TRUE)## $vertices
## + 2/30 vertices, named, from edc98e6:
## [1] Apache Creek Pueblo de los Muertos
##
## $distance
## [1] 44.6 Components and Bridges
Identifying fully connected subgraphs within a large network is a common analytical procedure and is quite straight forward in R using the igraph package. If you first want to know whether or not a given network is fully connected you can use the igraph::is_connected function to check.
igraph::is_connected(simple_net)## [1] FALSE
igraph::is_connected(simple_net_noiso)## [1] TRUEYou can also count components using the count_components function.
igraph::count_components(simple_net)## [1] 24.6.1 Identifying Components
If you want to decompose a network object into its distinct components you can use the igraph::decompose function which outputs a list object with each entry representing a distinct component. Each object in the list can then be called using [[k]] where k is the number of the item in the list.
components <- igraph::decompose(simple_net, min.vertices = 1)
components## [[1]]
## IGRAPH ef0c2ab UN-- 30 167 --
## + attr: name (v/c)
## + edges from ef0c2ab (vertex names):
## [1] Apache.Creek--Casa.Malpais Apache.Creek--Coyote.Creek
## [3] Apache.Creek--Hooper.Ranch Apache.Creek--Horse.Camp.Mill
## [5] Apache.Creek--Hubble.Corner Apache.Creek--Mineral.Creek.Pueblo
## [7] Apache.Creek--Rudd.Creek.Ruin Apache.Creek--Techado.Springs
## [9] Apache.Creek--Tri.R.Pueblo Apache.Creek--UG481
## [11] Apache.Creek--UG494 Atsinna --Cienega
## [13] Atsinna --Los.Gigantes Atsinna --Mirabal
## [15] Atsinna --Ojo.Bonito Atsinna --Pueblo.de.los.Muertos
## + ... omitted several edges
##
## [[2]]
## IGRAPH ef0c2bf UN-- 1 0 --
## + attr: name (v/c)
## + edges from ef0c2bf (vertex names):
V(components[[2]])$name## [1] "WS.Ranch"In the example here this network is fully connected with the exception of 1 node (WS Ranch). When you run the decompose function it separates WS ranch into a component as an isolate with no edges.
4.6.2 Cutpoints
A cutpoint is a node, the removal which creates a network with a higher number of components. There is not a convenient igraph function for identifying cutpoints but there is a function in the sna package within the statnet suite. Using the intergraph package we can easily convert an igraph object to a network object (using the asNetwork function) within the call to use this function.
The sna::cutpoint function returns the node id for any cutpoints detected. We can use the numbers returned to find the name of the node in question.
## [1] 18
V(simple_net)$name[cut_p]## [1] "Ojo.Bonito"
The example here reveals that Ojo Bonito is a cutpoint and if we look at the figure we can see that it is the sole connection with Baca Pueblo which would otherwise become and isolate and distinct component if Ojo Bonito were removed.
4.6.3 Bridges
A bridge is an edge, the removal of which results in a network with a higher number of components. The function igraph::min_cut finds bridges in network objects for sets of nodes or for the graph as a whole. The output of this function includes a vector called $cut which provides the edges representing bridges. By default this function only outputs the cut value but you can use the argument value.only = FALSE to get the full output.
min_cut(simple_net_noiso, value.only = FALSE)## $value
## [1] 1
##
## $cut
## + 1/167 edge from edc94c5 (vertex names):
## [1] Ojo Bonito--Baca Pueblo
##
## $partition1
## + 1/30 vertex, named, from edc94c5:
## [1] Baca Pueblo
##
## $partition2
## + 29/30 vertices, named, from edc94c5:
## [1] Apache Creek Casa Malpais Coyote Creek
## [4] Hooper Ranch Horse Camp Mill Hubble Corner
## [7] Mineral Creek Pueblo Rudd Creek Ruin Techado Springs
## [10] Tri-R Pueblo UG481 UG494
## [13] Atsinna Cienega Los Gigantes
## [16] Mirabal Ojo Bonito Pueblo de los Muertos
## [19] Scribe S Spier 170 Tinaja
## [22] Garcia Ranch Hinkson Heshotauthla
## [25] Jarlosa Pescado Cluster Yellowhouse
## [28] Foote Canyon Platt RanchAs this example illustrates the edge between Ojo Bonito and Baca Pueblo is a bridge (perhaps not surprising as Ojo Bonito was a cut point).
4.7 Cliques and Communities
Another very common task in network analysis involves creating cohesive sub-groups of nodes in a larger network. There are wide variety of methods available for defining such groups and we highlight a few of the most common here.
4.7.1 Cliques
A clique as a network science concept is arguably the strictest method of defining a cohesive subgroup. It is any set of three or more nodes in which each node is directly connected to all other nodes. It can be alternatively defined as a completely connected subnetwork, or a subnetwork with maximum density. The function igraph::max_cliques finds all maximal cliques in a network and outputs a list object with nodes in each set indicated. For the sake of space here we only output one clique of the 24 that were defined by this function call.
max_cliques(simple_net, min = 1)[[24]]## + 9/31 vertices, named, from edc90a4:
## [1] Los.Gigantes Cienega Tinaja Spier.170
## [5] Scribe.S Pescado.Cluster Mirabal Heshotauthla
## [9] YellowhouseNote in this list that the same node can appear in more than one maximal clique.
4.7.2 K-cores
A k-core is a maximal subnetwork in which each vertex has at least degree k within the subnetwork. In R this can be obtained using the igraph::coreness function and the filtering by value as appropriate. This function creates a vector of k values which can then be used to remove nodes as appropriate or symbolize them in plots.
# Define coreness of each node
kcore <- coreness(simple_net)
kcore[1:6]## Apache.Creek Atsinna Baca.Pueblo Casa.Malpais Cienega Coyote.Creek
## 9 8 1 9 9 9
# set up color scale
col_set <- heat.colors(max(kcore), rev = TRUE)
set.seed(2509)
plot(simple_net, vertex.color = col_set[kcore])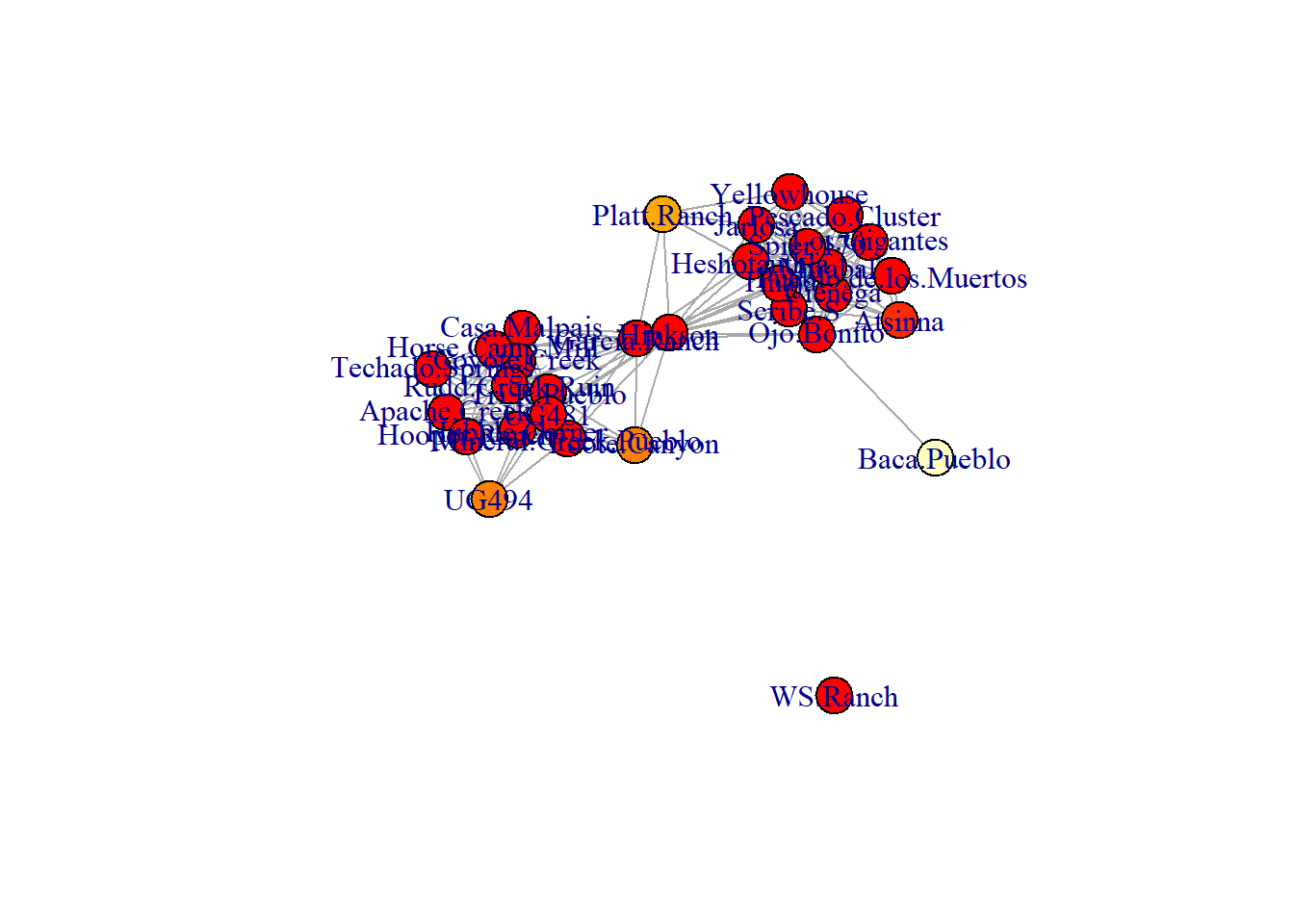
In the plot shown here the darker read colors represent higher maximal k-core values.
4.7.3 Cluster Detection Algorithms
R allows you to use a variety of common cluster detection algorithms to define groups of nodes in a network using a variety of different assumptions. We highlight a few of the most common here.
4.7.3.1 Girvan-Newman Clustering
Girvan-Newman clustering is a divisive algorithm based on betweenness that defines a partition of network that maximizes modularity by removing nodes with high betweenness iteratively (see discussion in Brughmans and Peeples 2023 Chapter 4.6). In R this is referred to as the igraph::edge.betweenness.community function. This function can be used on directed or undirected networks with or without edge weights. This function outputs a variety of information including individual edge betweenness scores, modularity information, and partition membership. See the help documents for more information
gn <- igraph::edge.betweenness.community(simple_net)## Warning: `edge.betweenness.community()` was deprecated in igraph 2.0.0.
## ℹ Please use `cluster_edge_betweenness()` instead.
## This warning is displayed once every 8 hours.
## Call `lifecycle::last_lifecycle_warnings()` to see where this warning was
## generated.
4.7.3.2 Walktrap Algorithm
The walktrap algorithm is designed to work for either binary or weighted networks and defines communities by generating a large number of short random walks and determining which sets of nodes consistently fall along the same short random walks. This can called using the igraph::cluster_walktrap function. The “steps” argument determines the length of the short walks and is set to 4 by default.
wt <- igraph::cluster_walktrap(simple_net, steps = 4)
set.seed(4353)
plot(simple_net, vertex.color = wt$membership)
4.7.3.3 Louvain Modularity
Louvain modularity is a cluster detection algorithm based on modularity. The algorithm iteratively moves nodes among community definitions in a way that optimizes modularity. This measure can be calculated on simple networks, directed networks, and weighted networks and is implemented in R through the igraph::cluster_louvain function.
lv <- igraph::cluster_louvain(simple_net)
set.seed(4353)
plot(simple_net, vertex.color = lv$membership)
4.7.3.4 Calculating Modularity for Partitions
If you would like to compare modularity scores among partitions of the same graph, this can be achieved using the igraph::modularity function. In the modularity call you simply supply an argument indicating the partition membership for each node. Note that this can also be used for attribute data such as regional designations. In the following chunk of code we will compare modularity for each of the clustering methods described above as well using subregion designations from the original Cibola region attribute data
# Modularity for Girvan-Newman
modularity(simple_net, membership = membership(gn))## [1] 0.4103589
# Modularity for walktrap
modularity(simple_net, membership = membership(wt))## [1] 0.4157195
# Modularity for Louvain clustering
modularity(simple_net, membership = membership(lv))## [1] 0.4131378
# Modularity for subregion
cibola_attr <- read.csv("data/Cibola_attr.csv")
modularity(simple_net, membership = as.factor(cibola_attr$Region))## [1] 0.1325612Note that although modularity can be useful in comparing among partitions like this approach has been shown to be poor at detecting small communities within a network so will not always be appropriate.
4.7.3.5 Finding Edges Within and Between Communities
In many cases you may be interested in identifying edges that remain within or extend between some network partition. This can be done using the igraph::crossing function. This function expects a igraph cluster definition object and an igraph network and will return a list of TRUE and FALSE values for each edge where true indicates an edge that extends beyond the cluster assigned to the nodes. Let’s take a look at the first 10 edges in our simple_net object based on the Louvain cluster definition.
igraph::crossing(lv, simple_net)[1:6]## Apache.Creek|Casa.Malpais Apache.Creek|Coyote.Creek
## FALSE FALSE
## Apache.Creek|Hooper.Ranch Apache.Creek|Horse.Camp.Mill
## FALSE FALSE
## Apache.Creek|Hubble.Corner Apache.Creek|Mineral.Creek.Pueblo
## FALSE FALSEBeyond this, if you plot an igraph object and add a cluster definition to the call it will produce a network graph with the clusters outlined and with nodes that extend between clusters shown in red.
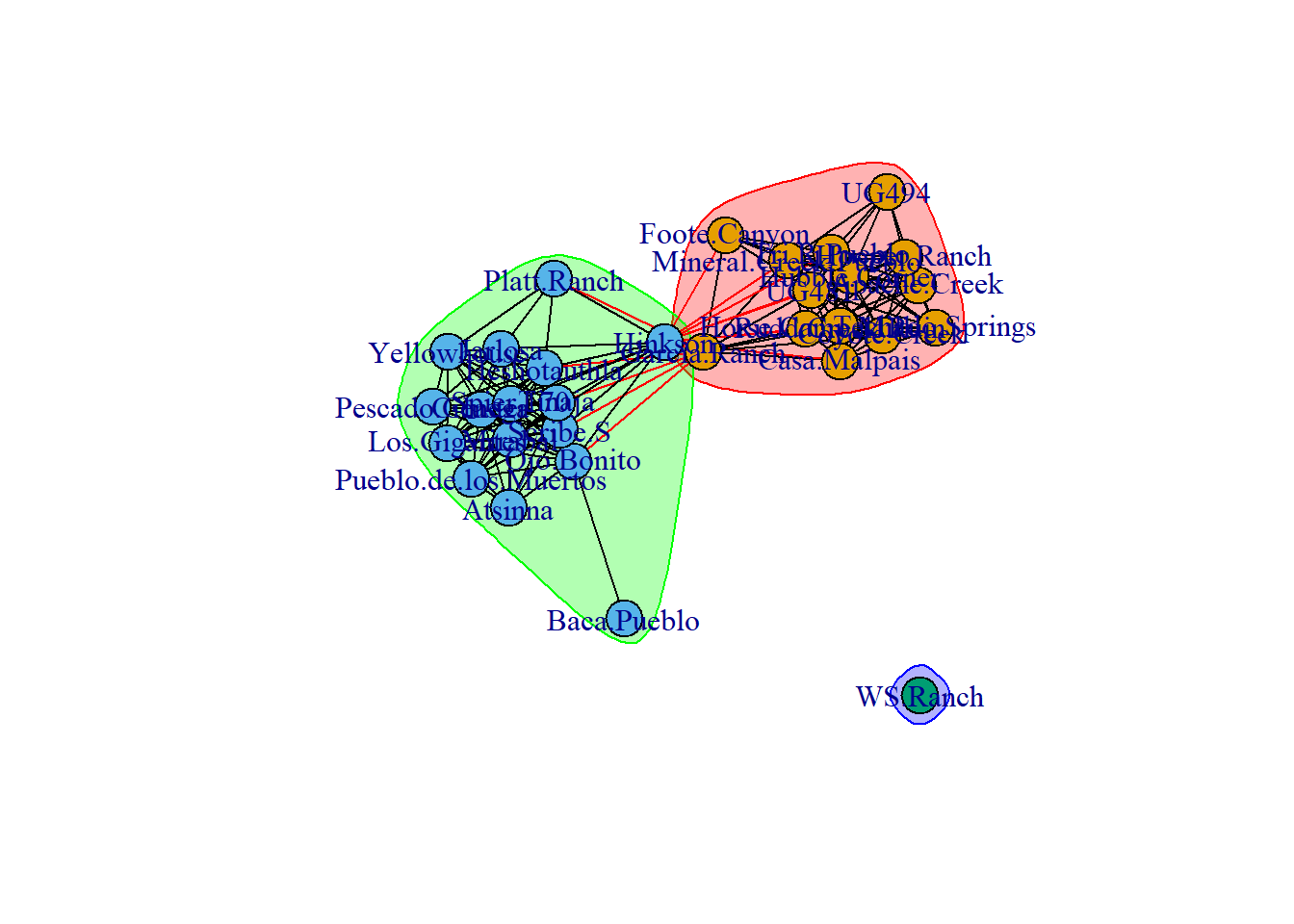
4.8 Case Study: Roman Roads
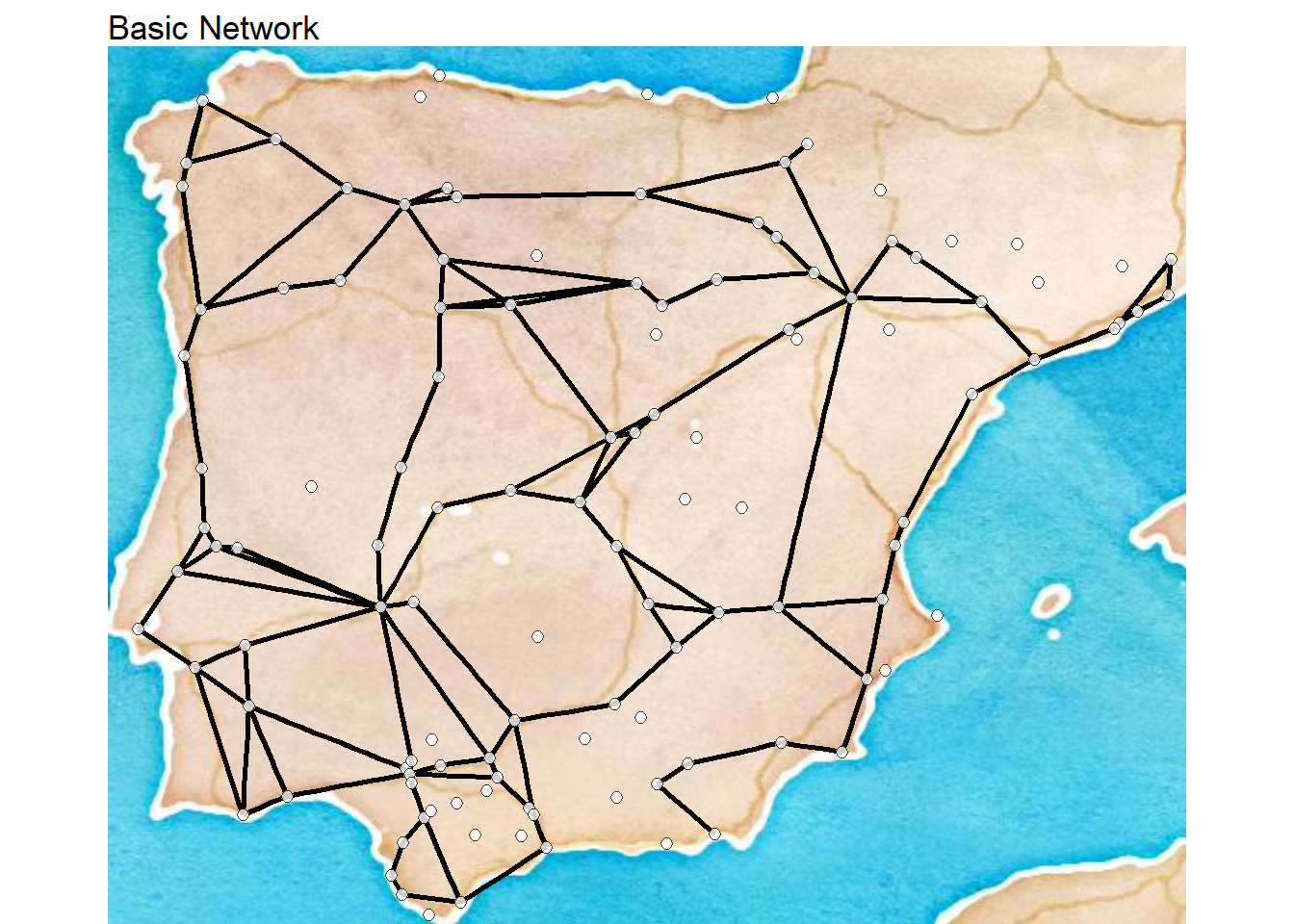
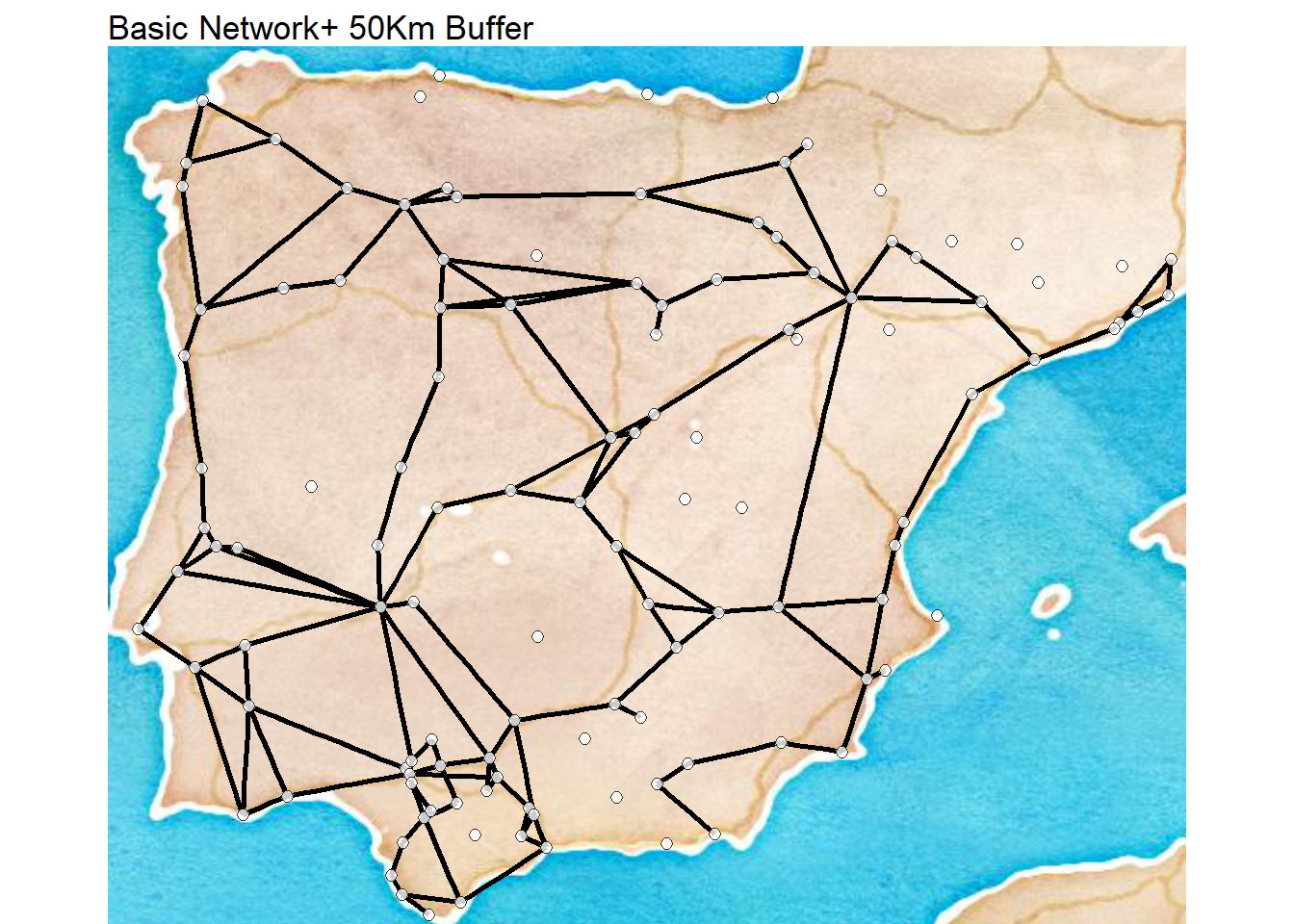
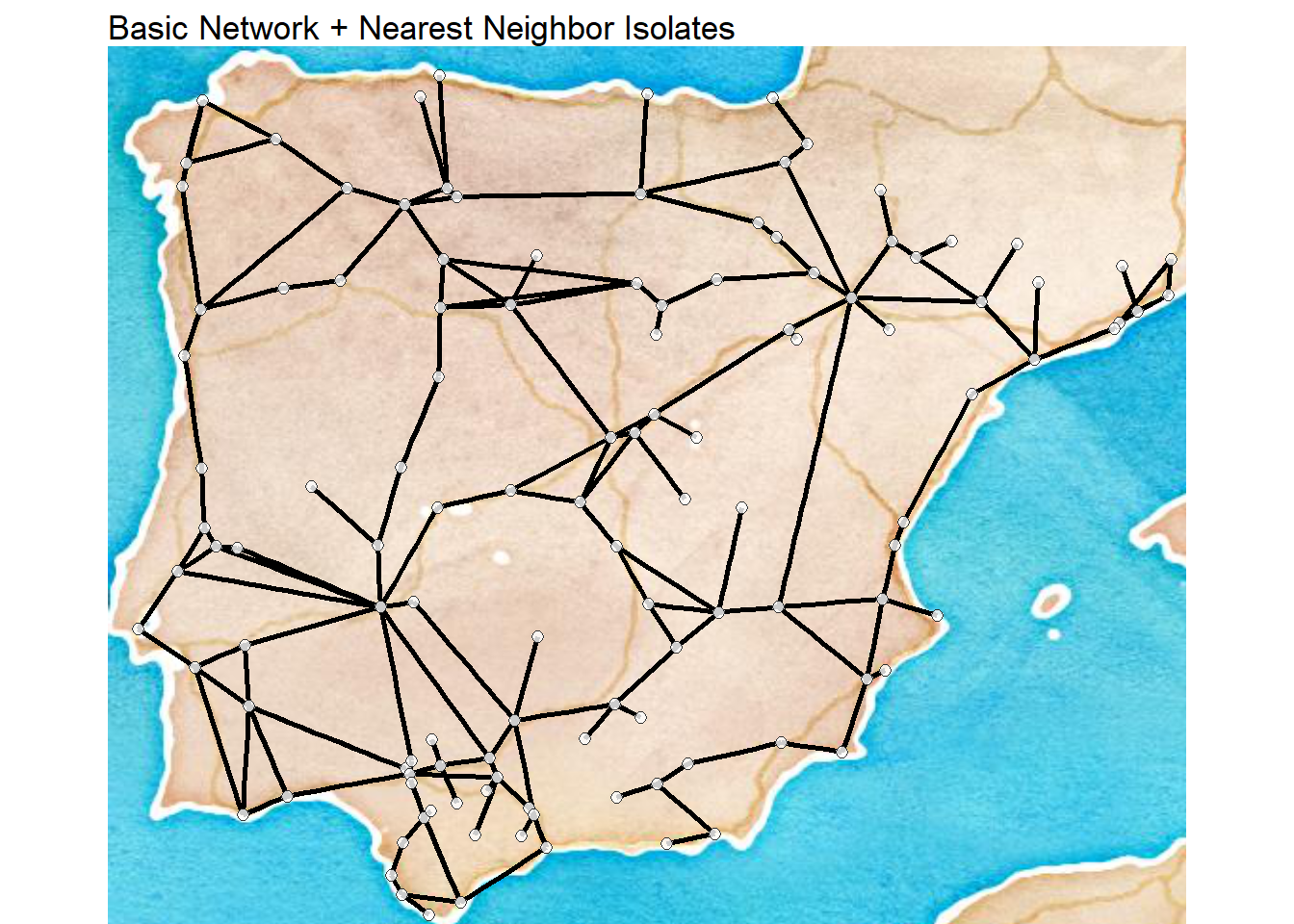
In the case study provided at the end of Chapter 4 of Brughmans and Peeples (2023) we take a simple network based on Roman era roads and spatial proximity of settlements in the Iberian Peninsula and calculate some basic exploratory network statistics. As described in the book, we can create different definitions and criteria for network edges and these can have impacts on the network and node level properties. In this case, we define three different networks as follows:
-
road_net- A basic network where every road connecting two settlements is an edge -
road_net2- A network that retains all of the ties of the above network but also connects isolated nodes that are within 50 Kms of one of the road network settlements -
road_net3- A network that retains all of the ties of the first road network but connects each isolate to its nearest neighbor among the road network settlements
First let’s read in the data file that contains all three networks and start by plotting them in turn on a map. We are using a custom network map function here that is save in a file called map_net.R that takes locations with decimal degrees locations and plots a network directly on a map. We will go over the specifics of the function in more detail in the Network Visualization and Spatial Networks sections but here we simply call the script directly from the .R file. Make sure you have the libraries initialized below to replicate this map.
library(igraph)
library(ggmap)
library(sf)
library(dplyr)
# Read in required data
load("data/road_networks.RData")
source("scripts/map_net.R")
# Create Basic network map
map_net(
nodes = nodes,
net = road_net,
bounds = c(-9.5, 36, 3, 43.8),
gg_maptype = "watercolor",
zoom_lev = 6,
map_title = "Basic Network"
)
# Create Basic network map
map_net(
nodes = nodes,
net = road_net2,
bounds = c(-9.5, 36, 3, 43.8),
gg_maptype = "watercolor",
zoom_lev = 6,
map_title = "Basic Network+ 50Km Buffer"
)
# Create Basic network map
map_net(
nodes = nodes,
net = road_net3,
bounds = c(-9.5, 36, 3, 43.8),
gg_maptype = "watercolor",
zoom_lev = 6,
map_title = "Basic Network + Nearest Neighbor Isolates"
)
Now that we’ve replicated the visuals, we want to replicate network statistics. Since we’re going to calculate several of the same network statistics for the networks in question, we can wrap this all into a function to save a bit of time. The following function expects an igraph network object and calculates each of the 10 variables show in the example in the book and returns them as a matrix.
Although the function below is somewhat long, it is very simple. It defines a function with a single argument net which is an igraph network object. It then creates an output matrix called out with the appropriate number of rows and columns and then populates the first column with the name of each measure. Next each network measure is evaluated in turn and assigned to the appropriate row in column 2 of the out matrix. Finally, the full matrix is returned: return(out).
library(igraph)
net_stats <- function(net) {
out <- matrix(NA, 10, 2)
out[, 1] <- c("Nodes", "Edges", "Isolates", "Density", "Average Degree",
"Average Shortest Path", "Diamater",
"Clustering Coefficient", "Closed Triad Count",
"Open Triad Count")
# number of nodes
out[1, 2] <- vcount(net)
# number of edges
out[2, 2] <- ecount(net)
# number of isolates
out[3, 2] <- sum(igraph::degree(net) == 0)
# network density rounding to the third digit
out[4, 2] <- round(edge_density(net), 3)
# mean degree rounding to the third digit
out[5, 2] <- round(mean(igraph::degree(net)), 3)
# mean shortest path length rounding to the third digit
out[6, 2] <- round(igraph::mean_distance(net), 3)
# network diameter
out[7, 2] <- igraph::diameter(net)
# average global transitivity rounding to the third digit
out[8, 2] <- round(igraph::transitivity(net, type = "average"), 3)
# closed triads in triad_census
out[9, 2] <- igraph::triad_census(net)[16]
# open triads in triad_census
out[10, 2] <- igraph::triad_census(net)[11]
return(out)
}Now let’s run it for each of the three networks in turn to reproduce the results in the book. We then combine the results into a single table that is nicely formatted using the kable function. If you’d prefer you can simply view the results of net_stats() right at the console.
ns1 <- net_stats(road_net)
ns2 <- net_stats(road_net2)
ns3 <- net_stats(road_net3)
ns_res <- cbind(ns1, ns2[, 2], ns3[, 2])
colnames(ns_res) <- c("Measure", "Basic Network", "50 Km Buffer",
"Nearest Neighbors")
knitr::kable(ns_res, format = "html")| Measure | Basic Network | 50 Km Buffer | Nearest Neighbors |
|---|---|---|---|
| Nodes | 122 | 122 | 122 |
| Edges | 127 | 144 | 160 |
| Isolates | 33 | 22 | 0 |
| Density | 0.017 | 0.02 | 0.022 |
| Average Degree | 2.082 | 2.361 | 2.623 |
| Average Shortest Path | 6.603 | 6.758 | 7.088 |
| Diamater | 15 | 15 | 16 |
| Clustering Coefficient | 0.162 | 0.199 | 0.136 |
| Closed Triad Count | 19 | 23 | 19 |
| Open Triad Count | 241 | 279 | 331 |
For an extended discussion of the Cranborne Chase case study and exponential random graph models click here