
Section 3 Network Data in R

A network is simply a set of entities and the formally defined relationships among them. There are, however, many different ways that networks can be encoded and displayed. This section provides examples of many of the most common network formats and data types discussed in Chapter 3 of Brughmans and Peeples 2023. For most of the examples below we use the Cibola technological similarity network data set (described in Chapter 2.8.3 and here) because it is relatively small and easy to display in a variety of formats.
Throughout this document, we refer to the unique bounded entities connected in a formal network as nodes and the connections between them as edges but note that there are many other terms used in the literature and in the documentation for the R packages used here. Nodes are often referred to as vertices or actors and edges are often referred to as ties or links. Note that we use network to refer to the formal system of interdependent pairwise relationships (edges) among a set of entities (nodes) but the term graph is often used equivalently in mathematics and other fields.
3.1 Network Data Formats
This section follows Chapter 3.2 in Brughmans and Peeples (2023) to provide examples of the same network and attribute data in a variety of different data formats as well as code for converting among these formats in R.
The network data formats we discuss in this section include:
- Edge list - A network data format consisting of a list of connected node pairs. E=((n1,n2),(n1,n3),(n1,n4),…,(ni,nj)). It can also be represented as a matrix with two columns for source and target nodes respectively and with one edge per row.
- Adjacency list - A network data format consisting of a set of rows, where the first node in each row is connected to all subsequent nodes in that same row.
- Adjacency matrix - A network data format consisting of a matrix of size n x n, with a set of rows equal to the number of nodes, and a set of columns equal to the number of nodes. When a pair of nodes is connected by an edge (i.e., when they are adjacent), then the corresponding cell will have an entry.
- Incidence matrix - A network data format consisting of a matrix of size n x e, with a set of rows equal to the number of nodes, and a set of columns equal to the number of edges. An entry is made in a cell if the corresponding node and edge are connected. Each column in the incidence matrix has two entries.
Let’s first get started by initializing all of the packages we will use in this section.
# initialize packages
library(igraph)
library(statnet)
library(intergraph)
library(vegan)
library(multinet)
The primary packages used in this Section (igraph,
statnet, and intergraph) are already described
in the last section. We also use here the
vegan package which includes many functions focused on
community ecology. In this document, we rely on this package to
calculate several distance/similarity metrics that are useful for
generating similarity networks.
Finally, we provide a brief example at the end of this section using
multinet which is a package focused on conducting multilayer network analyses.
3.1.1 Defining Network Objects in R
In general most of the examples of network data formats in the remainder of this section are converted into R network objects in two basic steps.
- First, we read in some external data file that contains network data, usually generated in some sort of spreadsheet program, and create an R data frame or matrix object.
- Next, we call a function that expects the given data format (edge list, adjacency matrix, incidence matrix, etc.) and converts it in to an R network object.
As you will see below, we mostly rely on igraph functions that take the following basic format:
igraph::graph_from_**DataType**
where **DataType** is replaced with the appropriate format such as edgelist, adjacency_matrix, and so on. In most of the examples below we then plot the network just to confirm that everything works, but that is certainly optional.
3.1.2 Edge List
The edge list is a very quick and easy way to capture network data. It simply lists the edges in the network one by one by node id: E=((n1,n2),(n1,n3),(n1,n4),…,(ni,nj)). For the purposes of data management it is usually easiest to create an edge list as a data frame or matrix where each row represents a pair of nodes with connections going from the node in one column to the node in the second column (additional columns can be used for edge weight or other edge attributes).
In this example, we import the Cibola data set in this format as a data frame and then convert it to an igraph network object for further analysis. You can download the edge list file here to follow along on your own. Since the edges in this network are undirected this will be a simple binary network, and we will use the directed = FALSE argument in the igraph::graph_from_edgelist function call. This function simply takes a edge list in tabular format and converts it to a network object R recognizes that can further be used for analysis and visualization.
# Read in edge list file as data frame
cibola_edgelist <-
read.csv(file = "data/Cibola_edgelist.csv", header = TRUE)
# Examine the first several rows
head(cibola_edgelist)## FROM TO
## 1 Apache Creek Casa Malpais
## 2 Apache Creek Coyote Creek
## 3 Apache Creek Hooper Ranch
## 4 Apache Creek Horse Camp Mill
## 5 Apache Creek Hubble Corner
## 6 Apache Creek Mineral Creek Pueblo
# Create graph object. The data frame is converted to a matrix as that
#is required by this specific function. Since this is an undirected
# network directed = FALSE.
cibola_net <-
igraph::graph_from_edgelist(as.matrix(cibola_edgelist),
directed = FALSE)
# Display igraph network object and then plot a simple node-link diagram
cibola_net## IGRAPH e6a6099 UN-- 30 167 --
## + attr: name (v/c)
## + edges from e6a6099 (vertex names):
## [1] Apache Creek--Casa Malpais Apache Creek--Coyote Creek
## [3] Apache Creek--Hooper Ranch Apache Creek--Horse Camp Mill
## [5] Apache Creek--Hubble Corner Apache Creek--Mineral Creek Pueblo
## [7] Apache Creek--Rudd Creek Ruin Apache Creek--Techado Springs
## [9] Apache Creek--Tri-R Pueblo Apache Creek--UG481
## [11] Apache Creek--UG494 Atsinna --Cienega
## [13] Atsinna --Los Gigantes Atsinna --Mirabal
## [15] Atsinna --Ojo Bonito Atsinna --Pueblo de los Muertos
## + ... omitted several edges
3.1.3 Adjacency List
The adjacency list consists of a set of rows, where the first node in each row is connected to all subsequent nodes in that same row. It is therefore more concise than the edge list (in which each relationship has its own row), but unlike the edge list it does not result in rows of equal length (each row in an edge list typically has two values, representing the pair of nodes). Adjacency lists are relatively rare in practice but can sometimes be useful formats for directly gathering network data in small networks and are supported by many network analysis software packages.
In the following chunk of code, we convert the network object we created above into an adjacency list using the igraph::as_adj_edge_list() function and examine a couple of the rows.
# Convert edge list to adjacency list using igraph function
adj_list <- igraph::as_adj_edge_list(cibola_net)
# examine adjacency list for the site Apache Creek
adj_list$`Apache Creek`## + 11/167 edges from e6a6099 (vertex names):
## [1] Apache Creek--Casa Malpais Apache Creek--Coyote Creek
## [3] Apache Creek--Hooper Ranch Apache Creek--Horse Camp Mill
## [5] Apache Creek--Hubble Corner Apache Creek--Mineral Creek Pueblo
## [7] Apache Creek--Rudd Creek Ruin Apache Creek--Techado Springs
## [9] Apache Creek--Tri-R Pueblo Apache Creek--UG481
## [11] Apache Creek--UG494
# It is also possible to call specific nodes by number. In this case,
# site 2 is Casa Malpais
adj_list[[2]]## + 11/167 edges from e6a6099 (vertex names):
## [1] Apache Creek--Casa Malpais Casa Malpais--Coyote Creek
## [3] Casa Malpais--Hooper Ranch Casa Malpais--Horse Camp Mill
## [5] Casa Malpais--Hubble Corner Casa Malpais--Rudd Creek Ruin
## [7] Casa Malpais--Techado Springs Casa Malpais--Tri-R Pueblo
## [9] Casa Malpais--UG481 Casa Malpais--Garcia Ranch
## [11] Casa Malpais--HinksonThe output for a particular node can be called by either referencing the name using using $ followed by the site name or [[k]] double brackets where k is the row number of the node in question. The printed output is essentially a list of all of the edges incident on the node in question identified by the name of the sending and receiving node.
3.1.4 Adjacency Matrix
The adjacency matrix is perhaps the most common and versatile network data format for data analysis in network science (in sociology it is sometimes referred to as the sociomatrix). It is a symmetric matrix of size n x n, with a set of rows and columns denoting the nodes in that network. The node names or identifiers are typically used to label both rows and columns. When a pair of nodes is connected by an edge (i.e. when they are adjacent), the corresponding cell will have an entry. The diagonal of this matrix represents “self loops” and can variously be defined as connected or unconnected depending on the application.
We can obtain an adjacency matrix object in R by converting our network object created above or by reading in a file directly with rows and columns denoting site and with 0 or 1 denoting the presence or absence of a relation. We take the data frame object adj_mat which is a square matrix of 1s and 0s and convert it into a network object using the igraph::graph_from_adjacency_matrix() function. You can download the csv file to follow along on your own here.
# Convert to adjacency matrix then display first few rows/columns
adj_mat <- igraph::as_adjacency_matrix(cibola_net)
adj_mat[1:5, 1:5]## 5 x 5 sparse Matrix of class "dgCMatrix"
## Apache Creek Casa Malpais Coyote Creek Hooper Ranch
## Apache Creek . 1 1 1
## Casa Malpais 1 . 1 1
## Coyote Creek 1 1 . 1
## Hooper Ranch 1 1 1 .
## Horse Camp Mill 1 1 1 1
## Horse Camp Mill
## Apache Creek 1
## Casa Malpais 1
## Coyote Creek 1
## Hooper Ranch 1
## Horse Camp Mill .
# Read in adjacency matrix and convert to network object for plotting
adj_mat2 <-
read.csv(file = "data/Cibola_adj.csv",
header = T,
row.names = 1)
adj_mat2[1:4, 1:4]## Apache.Creek Atsinna Baca.Pueblo Casa.Malpais
## Apache Creek 0 0 0 1
## Atsinna 0 0 0 0
## Baca Pueblo 0 0 0 0
## Casa Malpais 1 0 0 0
cibola_net2 <-
igraph::graph_from_adjacency_matrix(as.matrix(adj_mat2),
mode = "undirected")
set.seed(4352)
plot(cibola_net2)
Note when you compare this network graph to the one produced based on the edge list there is an additional unconnected node (WS Ranch) that was not shown in the previous network. This is one of the advantages of an adjacency matrix is it provides a way of easily including unconnected nodes without having to manually add them or include self-loops.
3.1.5 Incidence Matrix
An incidence matrix is most frequently used to define connections among different sets of nodes in a two-mode or bipartite network where the rows and columns represent two different classes of nodes and the presence/absence or value of an edge is indicated in the corresponding cell.
By way of example here we can read in the data that were used to generate the one-mode networks of ceramic technological similarity we have been examining so far. In the corresponding data frame, each row represents a site and each column represents a specific cluster of technological attributes in cooking pottery (see Peeples 2018, pg. 100-104 for more details) with the number in each cell representing the count of each technological cluster at each site.
After reading in this rectangular data frame, we can create a network object using the igraph::graph_from_incidence_matrix() function. We then plot it as a simple two-mode network with color representing node class. We discuss plotting options in greater detail in the visualization section of this document. You can download the csv file to follow along on your own here.
# Read in two-way table of sites and ceramic technological clusters
cibola_clust <-
read.csv(file = "data/Cibola_clust.csv",
header = TRUE,
row.names = 1)
head(cibola_clust)## Clust1 Clust2 Clust3 Clust4 Clust5 Clust6 Clust7 Clust8 Clust9
## Apache Creek 7 3 6 16 6 1 1 2 0
## Atsinna 0 12 26 5 0 1 6 0 7
## Baca Pueblo 0 9 3 12 1 2 5 0 16
## Casa Malpais 2 15 7 28 17 16 2 5 1
## Cienega 2 28 34 2 0 10 11 0 5
## Coyote Creek 10 13 8 30 20 5 1 8 0
## Clust10
## Apache Creek 0
## Atsinna 0
## Baca Pueblo 1
## Casa Malpais 0
## Cienega 1
## Coyote Creek 5
# Convert into a network object using the incidence matrix format. Note that
# multiple=TRUE as we want this defined as a bipartite network.
cibola_inc <-
igraph::graph_from_incidence_matrix(cibola_clust,
directed = FALSE,
multiple = TRUE)
head(cibola_inc)## 6 x 41 sparse Matrix of class "dgCMatrix"
##
## Apache Creek . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
## Atsinna . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
## Baca Pueblo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
## Casa Malpais . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
## Cienega . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
## Coyote Creek . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
##
## Apache Creek 3 6 16 6 1 1 2 . .
## Atsinna 12 26 5 . 1 6 . 7 .
## Baca Pueblo 9 3 12 1 2 5 . 16 1
## Casa Malpais 15 7 28 17 16 2 5 1 .
## Cienega 28 34 2 . 10 11 . 5 1
## Coyote Creek 13 8 30 20 5 1 8 . 5
set.seed(4543)
# Plot as two-mode network
plot(cibola_inc, vertex.color = as.numeric(V(cibola_inc)$type) + 1)
3.1.6 Node and Edge Information
Frequently we want to use other information about nodes and edges (node location, site type, edge weight, etc.) in our analyses and need to track these data in a separate attribute object or data column. One common way to do this is to simply create a data frame that contains the required attribute information and call specific data from this data frame when needed. As the following example shows, it is also possible to directly assign attributes to nodes or edges in an igraph network object and use those for subsequent analyses using the V() for nodes (V standing for vertices) and E() for edges calls within igraph.
In the following example we use this file which includes basic attribute data by site (node) for all sites in the network we’ve been working with here. This file includes x and y coordinates for the sites, information on the presence/absence and shape of Great Kiva public architectural features at those sites, and the Region to which they have been assigned. First we read in the data.
# Read in attribute data and look at the first few rows.
cibola_attr <- read.csv(file = "data/Cibola_attr.csv", header = TRUE)
head(cibola_attr)## Site x y Great.Kiva Region
## 1 Apache Creek 724125 3747310 Rectangular Great Kiva Mogollon Highlands
## 2 Atsinna 726741 3895499 none El Morro Valley
## 3 Baca Pueblo 651431 3797143 none Upper Little Colorado
## 4 Casa Malpais 659021 3786211 Rectangular Great Kiva Upper Little Colorado
## 5 Cienega 738699 3887985 none El Morro Valley
## 6 Coyote Creek 671154 3780509 Rectangular Great Kiva Upper Little ColoradoIn order to assign an attribute to a particular node or edge we can use the V and E (vertex and edge) calls in igraph. For example, in the following example, we will assign a region variable to each node in the network we created above using the V function to assign a vertex attribute. You simply type the name of the network object in the parenthesis after V and use the $ atomic variable symbol to assign a name to the attribute that will be associated with that network object.
# Assign a variable called "region" to the Cibola_net2 based on the
# column in the Cibola_attr table called "Region"
V(cibola_net2)$region <- cibola_attr$Region
# If we now call that attribute we get a vector listing each assigned value
V(cibola_net2)$region## [1] "Mogollon Highlands" "El Morro Valley" "Upper Little Colorado"
## [4] "Upper Little Colorado" "El Morro Valley" "Upper Little Colorado"
## [7] "Mogollon Highlands" "Carrizo Wash" "Pescado Basin"
## [10] "West Zuni" "Upper Little Colorado" "Mariana Mesa"
## [13] "Mariana Mesa" "West Zuni" "El Morro Valley"
## [16] "Vernon Area" "El Morro Valley" "West Zuni"
## [19] "Pescado Basin" "Carrizo Wash" "El Morro Valley"
## [22] "Upper Little Colorado" "El Morro Valley" "West Zuni"
## [25] "Mariana Mesa" "El Morro Valley" "Mariana Mesa"
## [28] "Mariana Mesa" "Mariana Mesa" "Mogollon Highlands"
## [31] "Pescado Basin"
# Note that "region" is now listed as an attribute when we view
# the network object
cibola_net2## IGRAPH e6c86d8 UN-- 31 167 --
## + attr: name (v/c), region (v/c)
## + edges from e6c86d8 (vertex names):
## [1] Apache.Creek--Casa.Malpais Apache.Creek--Coyote.Creek
## [3] Apache.Creek--Hooper.Ranch Apache.Creek--Horse.Camp.Mill
## [5] Apache.Creek--Hubble.Corner Apache.Creek--Mineral.Creek.Pueblo
## [7] Apache.Creek--Rudd.Creek.Ruin Apache.Creek--Techado.Springs
## [9] Apache.Creek--Tri.R.Pueblo Apache.Creek--UG481
## [11] Apache.Creek--UG494 Atsinna --Cienega
## [13] Atsinna --Los.Gigantes Atsinna --Mirabal
## [15] Atsinna --Ojo.Bonito Atsinna --Pueblo.de.los.Muertos
## + ... omitted several edgesThis can further be used for plotting or other analyses by calling the variable as a factor (see this resource or the Getting Started with R to learn more about the factor data.
3.2 Types of Networks
This section roughly follows Brughmans and Peeples (2023) Chapter 3.3 to describe and provide examples in R format of many of the most common types of networks. In the examples below we will use the igraph R package but we also show how to use the statnet and network packages where applicable.
In this section, we cover:
- Simple Networks - A set of nodes and a set of edges with no additional information about them.
- Directed Networks - A network consisting of a set of nodes and edges connecting them for which the orientation or direction is specified. In other words when A is connected to B, B is not necessarily connected to A.
- Signed, Categorized, and Weighted Networks - This category refers to networks where edges (relationships) have additional nominal, ordinal, or metric information encoded in them. A signed network is a network where the edges carry a positive or negative sign indicating some opposed property of relations in the network. A categorized network is a network where edges are classified according to some nominal category that does not necessarily represent an opposition. A weighted network is one in which the edges carry a non-binary value which indicates the strength of a given relationship.
- Two-Mode Networks - A network where two separate categories of nodes are defined with edges defined only between these categories.
- Similarity Networks - Networks where edges are defined or weighted based on a quantitative metric of similarity or distance based on node attributes or artifact assemblages.
- Ego Networks - A network including a focal node, the set of nodes the ego is connected to by an edge and the edges between nodes in this set.
- Multilayer Networks - A network where a single set of nodes is connected by two or more sets of edges that each represent a different kind of relationship among the nodes.
3.2.1 Simple Networks
We call a network a simple network (or simple graph) if we only have a set of nodes and a set of edges connecting them, with no additional information about the edges or specific rules they need to follow. Simple networks are, in other words, unweighted and undirected one-mode networks. By way of example we will use the Cibola region adjacency matrix file and convert it into a simple network using both igraph and network. Notice how in both examples we specify that this is an undirected network (mode = "undirected" and directed = FALSE).
# Read in raw adjacency matrix file
adj_mat2 <-
read.csv(file = "data/Cibola_adj.csv",
header = T,
row.names = 1)
# Convert to a network object using igraph
simple_net_i <-
igraph::graph_from_adjacency_matrix(as.matrix(adj_mat2),
mode = "undirected")
simple_net_i## IGRAPH e74b484 UN-- 31 167 --
## + attr: name (v/c)
## + edges from e74b484 (vertex names):
## [1] Apache.Creek--Casa.Malpais Apache.Creek--Coyote.Creek
## [3] Apache.Creek--Hooper.Ranch Apache.Creek--Horse.Camp.Mill
## [5] Apache.Creek--Hubble.Corner Apache.Creek--Mineral.Creek.Pueblo
## [7] Apache.Creek--Rudd.Creek.Ruin Apache.Creek--Techado.Springs
## [9] Apache.Creek--Tri.R.Pueblo Apache.Creek--UG481
## [11] Apache.Creek--UG494 Atsinna --Cienega
## [13] Atsinna --Los.Gigantes Atsinna --Mirabal
## [15] Atsinna --Ojo.Bonito Atsinna --Pueblo.de.los.Muertos
## + ... omitted several edges
# Covert to a network object using statnet/network
simple_net_s <-
network::network(as.matrix(adj_mat2), directed = FALSE)
simple_net_s## Network attributes:
## vertices = 31
## directed = FALSE
## hyper = FALSE
## loops = FALSE
## multiple = FALSE
## bipartite = FALSE
## total edges= 167
## missing edges= 0
## non-missing edges= 167
##
## Vertex attribute names:
## vertex.names
##
## No edge attributesNotice how the two formats differ in the way they internally store network data in R and the way they print output to the screen but that both show a total of 31 nodes (vertices) and 167 edges (for the igraph object the first row specifies node and edge numbers between the – marks).
3.2.2 Directed Networks
Sometimes relationships are directional, meaning they have an orientation. For example, the flow of a river is directed downstream. In such cases we can incorporate this information in our network data by distinguishing between the source and the target of an edge.
By way of example here we will modify the Cibola network edge list to remove some number of edges at random to simulate directed network data. We will then convert these data into various network and matrix formats to illustrate how directed networks are stored and used in R. We first use the sample function to define a sub-sample of our network nodes and then we create a network object from that random sub-sample. By randomly removing some edges from the edge list we are left with a directed network where not all edges will be reciprocated.
# Read in edge list file as data frame
cibola_edgelist <-
read.csv(file = "data/Cibola_edgelist.csv", header = TRUE)
# Create a random sub-sample of 125 edges out of the total 167 using
# the "sample" function
set.seed(45325)
el2 <- cibola_edgelist[sample(seq(1, nrow(cibola_edgelist)), 125,
replace = FALSE), ]
# Create graph object from the edge list using the directed=TRUE argument
# to ensure this is treated as a directed network object.
directed_net <-
igraph::graph_from_edgelist(as.matrix(el2), directed = TRUE)
directed_net## IGRAPH e74f18e DN-- 30 125 --
## + attr: name (v/c)
## + edges from e74f18e (vertex names):
## [1] Coyote Creek ->Techado Springs
## [2] Hubble Corner ->Tri-R Pueblo
## [3] Hubble Corner ->Techado Springs
## [4] Heshotauthla ->Pueblo de los Muertos
## [5] Rudd Creek Ruin->Techado Springs
## [6] Heshotauthla ->Hinkson
## [7] Los Gigantes ->Yellowhouse
## [8] Los Gigantes ->Pueblo de los Muertos
## + ... omitted several edges
# View as adjacency matrix of directed network object
(as_adjacency_matrix(directed_net))[1:5, 1:5]## 5 x 5 sparse Matrix of class "dgCMatrix"
## Coyote Creek Techado Springs Hubble Corner Tri-R Pueblo
## Coyote Creek . 1 1 .
## Techado Springs . . . 1
## Hubble Corner . 1 . 1
## Tri-R Pueblo . . . .
## Heshotauthla . . . .
## Heshotauthla
## Coyote Creek .
## Techado Springs .
## Hubble Corner .
## Tri-R Pueblo .
## Heshotauthla .
Notice that when we look at the igraph network plot it has arrows indicating the direction of connection in the edge list. If you are making your own directed edge list, the sending node by default will be in the first column and the receiving node in the second column. In the adjacency matrix the upper and lower triangles are no longer identical. Again, if you are generating your own adjacency matrix, you can simply mark edges sent from nodes denoted as rows and edges received from the same nodes as columns. Finally, in the plot, since R recognizes this as a directed igraph object when we plot the network, it automatically shows arrows indicating the direction of the edge.
3.2.3 Signed, Categorized, and Weighted Networks
In many situations we want to add values to specific edges such as signs (sometimes called valences), nominal categories, or weights defining the strength or nature of relationships. There are a variety of ways that we can record and assign such weights or values to edges in R. The simplest way is to directly include that information in one of the formats described above such as an edge list or adjacency matrix. For example, we can add a third column to an edge list that denotes the weight, category, or sign of each edge or can fill the cells in an adjacency matrix with specific values rather than simply 1s or 0s.
In this example, we will randomly generate edge weights for the Cibola network edge list and adjacency matrix to illustrate how R handles these formats. We use the sample function again to create a random vector of values between 1 and 4 for every edge in the network and then add it to the edge list as a new variable called $Weight. We then convert this data frame into a network object.
# Read in edge list file as data frame
cibola_edgelist <-
read.csv(file = "data/Cibola_edgelist.csv", header = TRUE)
# Add additional column of weights as random integers between 1 and 4
# for each edge
cibola_edgelist$weight <-
sample(seq(1, 4), nrow(cibola_edgelist), replace = TRUE)
# Create weighted network object calling only the first two columns
weighted_net <-
igraph::graph_from_edgelist(as.matrix(cibola_edgelist[, 1:2]),
directed = FALSE)
# add edge attribute to indicate weight
E(weighted_net)$weight <- cibola_edgelist$weight
# Explore the first few rows and columns of network object
head(get.data.frame(weighted_net))## from to weight
## 1 Apache Creek Casa Malpais 4
## 2 Apache Creek Coyote Creek 1
## 3 Apache Creek Hooper Ranch 1
## 4 Apache Creek Horse Camp Mill 3
## 5 Apache Creek Hubble Corner 4
## 6 Apache Creek Mineral Creek Pueblo 4
# View network as adjacency matrix. Notice the attr="weight" command that
# indicates which edge attribute to use for values in the matrix
head(as_adjacency_matrix(weighted_net, attr = "weight"))[1:5, 1:5]## 5 x 5 sparse Matrix of class "dgCMatrix"
## Apache Creek Casa Malpais Coyote Creek Hooper Ranch
## Apache Creek . 4 1 1
## Casa Malpais 4 . 1 1
## Coyote Creek 1 1 . 1
## Hooper Ranch 1 1 1 .
## Horse Camp Mill 3 2 4 4
## Horse Camp Mill
## Apache Creek 3
## Casa Malpais 2
## Coyote Creek 4
## Hooper Ranch 4
## Horse Camp Mill .
Notice in the final plot that line thickness is used to indicate edges with various weights. We will explore further options for such visualizations in the network visualizations section of this document.
3.2.4 Two-mode Networks and Affiliation Networks
Two-mode networks are networks where two separate categories of nodes are defined with a structural variable (edges) between these categories. In sociology, two-mode networks are often used for studying the affiliation of individuals with organizations, such as the presence of professionals on the boards of companies or the attendance of scholars at conferences (referred to as affiliation networks).
Two-mode network data are typically recorded in a two-way table with rows and columns representing two different classes of nodes and with individual cells representing the presence/absence or weight of edges between those classes of nodes. By way of example here we will return to the table of ceramic technological clusters by sites for the Cibola region data. The simplest way to create an unweighted two-mode network from these data is to create a network object directly from a two-way table as we saw above. In this example this will create an edge between each site and each technological cluster present there irrespective of relative frequency using the igraph::graph_from_incidence_matrix function.
# Read in two-way table of sites and ceramic technological clusters
cibola_clust <- read.csv(file = "data/Cibola_clust.csv",
header = TRUE,
row.names = 1)
# Create network from incidence matrix based on presence/absence of
# a cluster at a site
cibola_inc <- igraph::graph_from_incidence_matrix(cibola_clust,
directed = FALSE,
multiple = TRUE)
cibola_inc## IGRAPH e778055 UN-B 41 2214 --
## + attr: type (v/l), name (v/c)
## + edges from e778055 (vertex names):
## [1] Apache Creek--Clust1 Apache Creek--Clust1 Apache Creek--Clust1
## [4] Apache Creek--Clust1 Apache Creek--Clust1 Apache Creek--Clust1
## [7] Apache Creek--Clust1 Apache Creek--Clust2 Apache Creek--Clust2
## [10] Apache Creek--Clust2 Apache Creek--Clust3 Apache Creek--Clust3
## [13] Apache Creek--Clust3 Apache Creek--Clust3 Apache Creek--Clust3
## [16] Apache Creek--Clust3 Apache Creek--Clust4 Apache Creek--Clust4
## [19] Apache Creek--Clust4 Apache Creek--Clust4 Apache Creek--Clust4
## [22] Apache Creek--Clust4 Apache Creek--Clust4 Apache Creek--Clust4
## + ... omitted several edges
set.seed(4537643)
# Plot as two-mode network
plot(cibola_inc, vertex.color = as.numeric(V(cibola_inc)$type) + 1)
In this case since most clusters are present at most sites, this creates a pretty busy network that may not be particularly useful. An alternative to this is to define some threshold (either in terms of raw count or proportion) to define an edge between a node of one class and another. We provide an example here and build a function that you could modify to do this for your own data. In this function you can set the proportion threshold that you would like to used to define an edge between two classes of nodes. If the proportion of that cluster at that site is greater than or equal to that threshold an edge will be present. In the example below the threshold is set at 0.25 meaning that we will define edges between nodes that share a common type that makes of at least a quarter of the assemblage of both sites.
# Define function for creating incidence matrix with threshold
two_mode <- function(x, thresh = 0.25) {
# Create matrix of proportions from x input into function
temp <- prop.table(as.matrix(x), 1)
# Define anything with greater than or equal to threshold as
# present (1)
temp[temp >= thresh] <- 1
# Define all other cells as absent (0)
temp[temp < 1] <- 0
# Return the new binarized table as output of the function
return(temp)
}
# Run the function and create network object
# thresh is set to 0.25 but could be any values from 0-1
mod_clust <- two_mode(cibola_clust, thresh = 0.25)
# Examine the first few rows
head(mod_clust)## Clust1 Clust2 Clust3 Clust4 Clust5 Clust6 Clust7 Clust8 Clust9
## Apache Creek 0 0 0 1 0 0 0 0 0
## Atsinna 0 0 1 0 0 0 0 0 0
## Baca Pueblo 0 0 0 0 0 0 0 0 1
## Casa Malpais 0 0 0 1 0 0 0 0 0
## Cienega 0 1 1 0 0 0 0 0 0
## Coyote Creek 0 0 0 1 0 0 0 0 0
## Clust10
## Apache Creek 0
## Atsinna 0
## Baca Pueblo 0
## Casa Malpais 0
## Cienega 0
## Coyote Creek 0
# Create a graph matrix from the new incidence matrix
two_mode_net <- igraph::graph_from_incidence_matrix(
mod_clust,
directed = FALSE,
multiple = TRUE)
# Plot results
set.seed(4537)
plot(two_mode_net,
vertex.color = as.numeric(V(cibola_inc)$type) + 1)
Notice how there are now far fewer edges and if you are familiar with the sites in question you might notice some clear regional patterning.
It is also possible to create one-mode projections of the two-mode data here using simple matrix algebra. All you need to do is multiply a matrix by the transpose of that matrix. The results will be a adjacency matrix for whichever set of nodes represented the rows in the first matrix in the matrix multiplication. Here is an example using the mod_clust incidence matrix with threshold created above. In the resulting incidence matrix individual cells will represent the number of different edges in common between the nodes in question and can be treated like an edge weight. The diagonal of the matrix will be the total number of clusters that were present in a site assemblage. In R the operator %*% indicates matrix multiplication and the function t() will transpose a given matrix.
# In R the command "%*%" indicates matrix multiplication and "t()"
# gives the transpose of the matrix within the parentheses.
# Lets first create a one-mode projection focused on sites
site_mode <- mod_clust %*% t(mod_clust)
site_net <- igraph::graph_from_adjacency_matrix(site_mode,
mode = "undirected",
diag = FALSE)
plot(site_net)
# Now lets create a one-mode projection focused on ceramic
# technological clusters.
# Notice that the only change is we switch which side of the
# matrix multiplication we transpose.
clust_mode <- t(mod_clust) %*% mod_clust
head(clust_mode)## Clust1 Clust2 Clust3 Clust4 Clust5 Clust6 Clust7 Clust8 Clust9 Clust10
## Clust1 1 0 0 0 0 0 0 0 0 0
## Clust2 0 16 9 1 0 2 0 0 0 0
## Clust3 0 9 10 0 0 1 0 0 0 0
## Clust4 0 1 0 11 1 0 0 0 0 0
## Clust5 0 0 0 1 1 0 0 0 0 0
## Clust6 0 2 1 0 0 2 0 0 0 0
clust_net <- igraph::graph_from_adjacency_matrix(clust_mode,
mode = "undirected",
diag = FALSE)
plot(clust_net)
3.2.5 Similarity Networks
Similarity networks simply refer to one-mode networks where nodes are defined as entities of interest with edges defined and/or weighted based on some metric of similarity (or distance) defined based on the features, attributes, or assemblage associated with that node. Such an approach is frequently used in archaeology to explore material cultural networks where nodes are contexts of interests (e.g., sites, excavation units, houses, etc.) and edges are defined or weighted based on similarities in the relative frequencies of artifacts or particular classes of artifacts recovered in those contexts.
There are many different ways to define and track similarity network data for use in R. In this example, we will show several methods using the affiliation data we used in the previous example. Specifically, we will define and weight edges based on similarities in the frequencies of ceramic technological clusters at sites in our Cibola region sample.
For most of these examples we will use the statnet package and the network package object format within it rather than igraph because statnet has a few additional functions that are useful when working with similarity data. In the following examples, we will first demonstrate several different similarity/distance metrics and then discuss approaches to binarization of these similarity networks and other options for working with weighted data.
Brainerd-Robinson Similarity
The first metric we will explore here is a rescaled version of the Brainerd-Robinson (BR) similarity metric. This BR measure is commonly used in archaeology including in a number of recent (and not so recent) network studies. This measure represents the total similarity in proportional representation of categories and is defined as:
\[S = {\frac{2-\sum_{k} \left|x_{k} - y_{k}\right|} {2}}\]
where, for all categories \(k\), \(x\) is the proportion of \(k\) in the first assemblage and \(y\) is the proportion of \(k\) in the second. We subtract the sum from 2 as 2 is the maximum proportional difference possible between two samples. We further divide the result by 2. This provides a scale of similarity from 0 to 1 where 1 is perfect similarity and 0 indicates no similarity. The chunk below defines the code for calculating this modified BR similarity measure. Note here we use a distance metric called “Manhattan Distance” built into the vegan package in R. This metric is identical to the Brainerd-Robinson metric. We rescale our results to range from 0 to 1 after calculation.
# Read in raw data
cibola_clust <-
read.csv(file = "data/Cibola_clust.csv",
header = TRUE,
row.names = 1)
# First we need to convert the ceramic technological clusters into proportions
clust_p <- prop.table(as.matrix(cibola_clust), margin = 1)
# The following line uses the vegdist function in the vegan package
# to calculate the Brainerd-Robinson similarity score. Since vegdist
# by default defines an unscaled distance we must subtract the results
# from 2 and then divide by 2 to get a similarity scaled from 0 to 1.
cibola_br <- ((2 - as.matrix(vegan::vegdist(clust_p,
method = "manhattan"))) / 2)
# Lets look at the first few rows.
cibola_br[1:4, 1:4]## Apache Creek Atsinna Baca Pueblo Casa Malpais
## Apache Creek 1.0000000 0.3433584 0.4455782 0.7050691
## Atsinna 0.3433584 1.0000000 0.5750090 0.3740804
## Baca Pueblo 0.4455782 0.5750090 1.0000000 0.5608953
## Casa Malpais 0.7050691 0.3740804 0.5608953 1.0000000At this point we could simply define this as a weighted network object where weights are equal to the similarity scores, or we could define a threshold for defining edges as present or absent. We will discuss these options in detail after presenting other similarity/distance metrics.
3.2.5.1 Morisita’s Overlap Index
Another measure that has been used for defining similarities among assemblages for archaeological similarity networks is Morisita’s overlap index. This measure is a measure of the overlap of individual assemblages within a larger population that takes the size of samples into account. Specifically, the approach assumes that as sample size increases diversity will likely increase. This measure produces results that are very similar to the Brainerd-Robinson metric in practice in most cases but this measure may be preferred where there are dramatic differences in assemblage sizes among observations.
Morisita’s index is calculated as:
\[C_D=\frac{2 \Sigma^Sx_iy_i}{(D_x + D_y)XY}\]
where
- \(x_i\) is the number of rows where category \(i\) is represented in the total \(X\) from the population.
- \(y_i\) is the number of rows where category \(i\) is presented in the total \(Y\) from the population.
- \(D_x\) and \(D_y\) are the Simpson’s diversity index values for \(x\) and \(y\) respectively.
- \(S\) is the total number of columns.
This metric ranges from 0 (where no categories overlap at all) to 1 where the categories occur in the same proportions in both samples. Because this metric works on absolute counts we can run the vegdist function directly on the Cibola_clust object. Because we want a similarity rather than a distance (which is the default for this function in R) we subtract the results from 1.
# Calculate matrix of Morisita similarities based on the
# Cibola_clust two-way table.
cibola_mor <- 1 - as.matrix(vegan::vegdist(cibola_clust,
method = "morisita"))
cibola_mor[1:4, 1:4]## Apache Creek Atsinna Baca Pueblo Casa Malpais
## Apache Creek 1.0000000 0.4885799 0.6014729 0.9060751
## Atsinna 0.4885799 1.0000000 0.5885682 0.4459998
## Baca Pueblo 0.6014729 0.5885682 1.0000000 0.6529069
## Casa Malpais 0.9060751 0.4459998 0.6529069 1.0000000\(\chi^{2}\) Distance
The next measure we will use is the \(\chi^{2}\) distance metric which is the basis of correspondence analysis and related methods commonly used for frequency seriation in archaeology (note that this should probably really be called the \(\chi\) distance since the typical form we use is not squared, but the name persists this way in the literature so that’s what we use here). This measure is defined as:
\[\chi_{jk} = \sqrt{\sum \frac 1{c_{j}} ({x_{j}-y_{j})^{2}}}\]
where \(c_j\) denotes the \(j_{th}\) element of the average row profile (the proportional abundance of \(j\) across all rows) and \(x\) and \(y\) represent row profiles for the two sites under comparison. This metric therefore takes raw abundance (rather than simply proportional representation) into account when defining distance between sites. The definition of this metric is such that rare categories play a greater role in defining distances among sites than common categories (as in correspondence analysis). This measure has a minimum value of 0 and no theoretical upper limit.
The code for calculating \(\chi^{2}\) distances is defined in the chunk below and a new object called Cibola_X is created using this measure. It is sometimes preferable to rescale this measure so that it is bounded between 0 and 1. We create a second object called Cibola_X01 which represents rescaled distances by simply dividing the matrix by the maximum observed value (there are many other ways to do this but this will be fine for our demonstration purposes). Again, we subtract these results from 1 to convert a distance to a similarity.
# Define function for calculating chi-squared distance
chi_dist <- function(x) {
# calculates the profile for every row
rowprof <- x / apply(x, 1, sum)
# calculates the average profile
avgprof <- apply(x, 2, sum) / sum(x)
# creates a distance object of chi-squared distances
chid <- dist(as.matrix(rowprof) %*% diag(1 / sqrt(avgprof)))
# return the results
return(as.matrix(chid))
}
# Run the script and then create the rescaled 0-1 version
cibola_x <- chi_dist(cibola_clust)
cibola_x01 <- 1 - (cibola_x / max(cibola_x))
cibola_x01[1:4, 1:4]## Apache Creek Atsinna Baca Pueblo Casa Malpais
## Apache Creek 1.0000000 0.2904662 0.1010795 0.6166508
## Atsinna 0.2904662 1.0000000 0.3393173 0.2999925
## Baca Pueblo 0.1010795 0.3393173 1.0000000 0.1469591
## Casa Malpais 0.6166508 0.2999925 0.1469591 1.0000000Jaccard Similarity
In many situations we may have either only presence/absence data or data where a one or a few categories dominate the assemblages of most sites. In the former case, the measures of similarity above will not work. In the latter case, although the measures above may work, the results may largely be a product of similarities or differences in those few common categories. In such cases, it may be preferable to use a similarity metric based on presence/absence data. The Jaccard similarity coefficient for two sets of presence/absence values is simply the intersection of values in those two cases divided by the union of those two cases. Formally this can be written as:
\[J(A,B) = \frac{|A \cap B|}{|A \cup B|} = \frac{|A \cap B|}{|A| + |B| - |A \cap B|}\]
where
- \(|A \cap B|\) is the intersection of vectors A and B or the number of categories where both vectors = present.
- \(|A \cup B|\) is the union of vectors A and B or the total number of categories where either A or B is present.
We can define a simple function in R to calculate Jaccard similarity coefficients. These values will always range from 0 (no categories in common) to 1 (all categories in common).
jaccard <- function(a, b) {
intersection <- length(which((a-b) == 0))
union <- length(a) + length(b) - intersection
return(intersection / union)
}In order to try this function out, we will create three simple vectors of values and then compare them. Note that this function compares matches for the position of each item in the vector. So if vec1[1] = 1 and vec2[1] = 1 that is considered a match:
vec1 <- c(0, 1, 1, 0, 1, 0, 0, 1, 0, 1, 0)
vec2 <- c(0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 1)
vec3 <- c(0, 1, 0, 0, 0, 0, 1, 0, 0, 1, 1)
jaccard(vec1, vec2)## [1] 0.4666667
jaccard(vec2, vec3)## [1] 0.5714286
jaccard(vec1, vec3)## [1] 0.375If we want to run this for an entire incidence matrix we could roll it into another function. Note that this function automatically takes an incidence matrix, converts it into presence/absence data and then calculates Jaccard coefficients for every pair of nodes. The output is a square matrix of similarities from row to row. Let’s try it out in our cibola_clust data we used above:
jaccard_inc <- function(dat) {
dat[dat > 0] <- 1
out <- matrix(NA, nrow(dat), nrow(dat))
for (i in seq_len(nrow(dat))) {
for (j in seq_len(nrow(dat))) {
out[i, j] <- jaccard(dat[i, ], dat[j, ])
}
}
return(out)
}
cibola_j <- jaccard_inc(dat = cibola_clust)
cibola_j[1:4, 1:4]## [,1] [,2] [,3] [,4]
## [1,] 1.0000000 0.4285714 0.4285714 0.8181818
## [2,] 0.4285714 1.0000000 0.6666667 0.5384615
## [3,] 0.4285714 0.6666667 1.0000000 0.5384615
## [4,] 0.8181818 0.5384615 0.5384615 1.0000000Note that we have created R scripts with the two functions above as separate files. If you would like to initialize those functions without copying and pasting the code above, you can use the source() function to call a function straight from a file. These are both located in the “scripts” folder so we add that sub-folder to the file name in the argument. Click here to download jaccard.R and here for jaccard_inc.R.
Creating Network Objects from Similarity Matrices
Now that we have defined our measures of similarity, the next step is to convert these into network objects that our R packages will be able to work with. We can do this by either creating binary networks (where ties are either present or absent) or weighted networks (which in many cases are simply the raw similarity/distance matrices we calculated above). We will provide examples of both approaches, starting with simple binary networks. There are many ways to define networks from matrices like those we generated above and our examples below should not been seen as an exhaustive set of procedures.
Creating binary network objects
First, we will produce a network object based on our BR similarity matrix created above. In this example, we define ties as present between pairs of sites when they share more than 65% commonality (BR > 0.65) in terms of the proportions of ceramics recovered from pairs of sites.
In the code below, the event2dichot function (from the statnet package) takes our matrix and divides it into 1s and 0s based on the cut off we choose. Here we’re using and absolute cut off meaning we’re assigning a specific value to use as the cut off (0.65). We then send the output of this function to the network function just as before.
# Define our binary network object from BR similarity
brnet <-
network(event2dichot(cibola_br,
method = "absolute",
thresh = 0.65),
directed = FALSE)
# Now let's add names for our nodes based on the row names
# of our original matrix
brnet %v% "vertex.names" <- row.names(cibola_clust)
# look at the results.
brnet## Network attributes:
## vertices = 31
## directed = FALSE
## hyper = FALSE
## loops = FALSE
## multiple = FALSE
## bipartite = FALSE
## total edges= 167
## missing edges= 0
## non-missing edges= 167
##
## Vertex attribute names:
## vertex.names
##
## No edge attributes
In the next chunk of code we will use the \(\chi^2\) distances to create binary networks. This time, we will not use an absolute value to define ties as present, but instead will define those similarities greater than 80 percent of all similarities as present. We will then once again plot just as above.
# Note we use 1 minus chacoX01 here so to convert a distance
# to a similarity
xnet <-
network(event2dichot(cibola_x01,
method = "quantile",
thresh = 0.80),
directed = FALSE)
# Once again add vertex names as row names of data frame
xnet %v% "vertex.names" <- row.names(cibola_clust)
# look at the results
xnet## Network attributes:
## vertices = 31
## directed = FALSE
## hyper = FALSE
## loops = FALSE
## multiple = FALSE
## bipartite = FALSE
## total edges= 80
## missing edges= 0
## non-missing edges= 80
##
## Vertex attribute names:
## vertex.names
##
## No edge attributes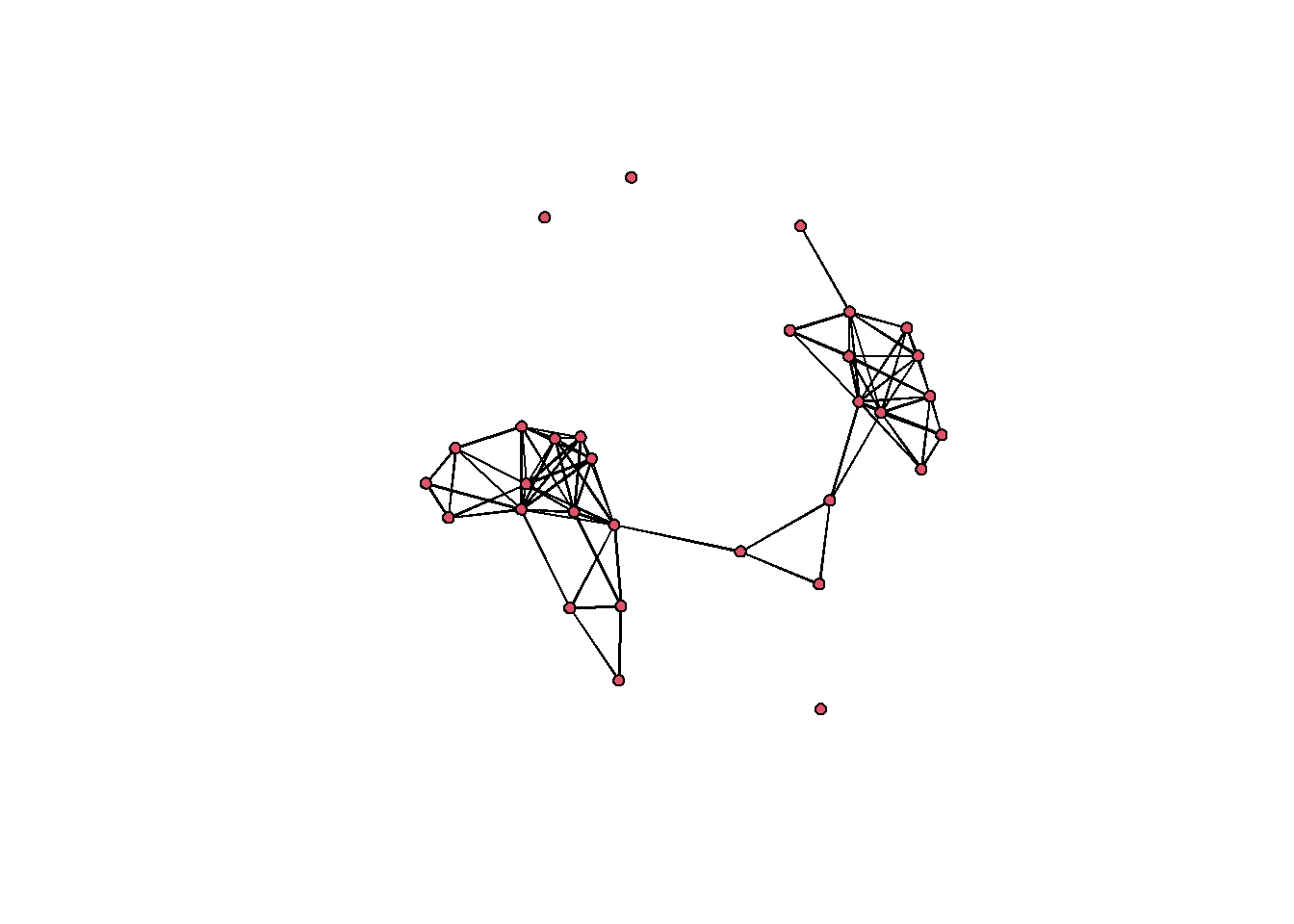
Finally, we’ll use our Jaccard coefficients and we will define our threshold for defining edges as present or absent as the grand mean of the entire similarity matrix using method = "mean". There are more options in the event2dichot function. See the help material for more.
jnet <-
network(event2dichot(cibola_j,
method = "mean"),
directed = FALSE)
jnet %v% "vertex.names" <- row.names(cibola_clust)
jnet## Network attributes:
## vertices = 31
## directed = FALSE
## hyper = FALSE
## loops = FALSE
## multiple = FALSE
## bipartite = FALSE
## total edges= 207
## missing edges= 0
## non-missing edges= 207
##
## Vertex attribute names:
## vertex.names
##
## No edge attributes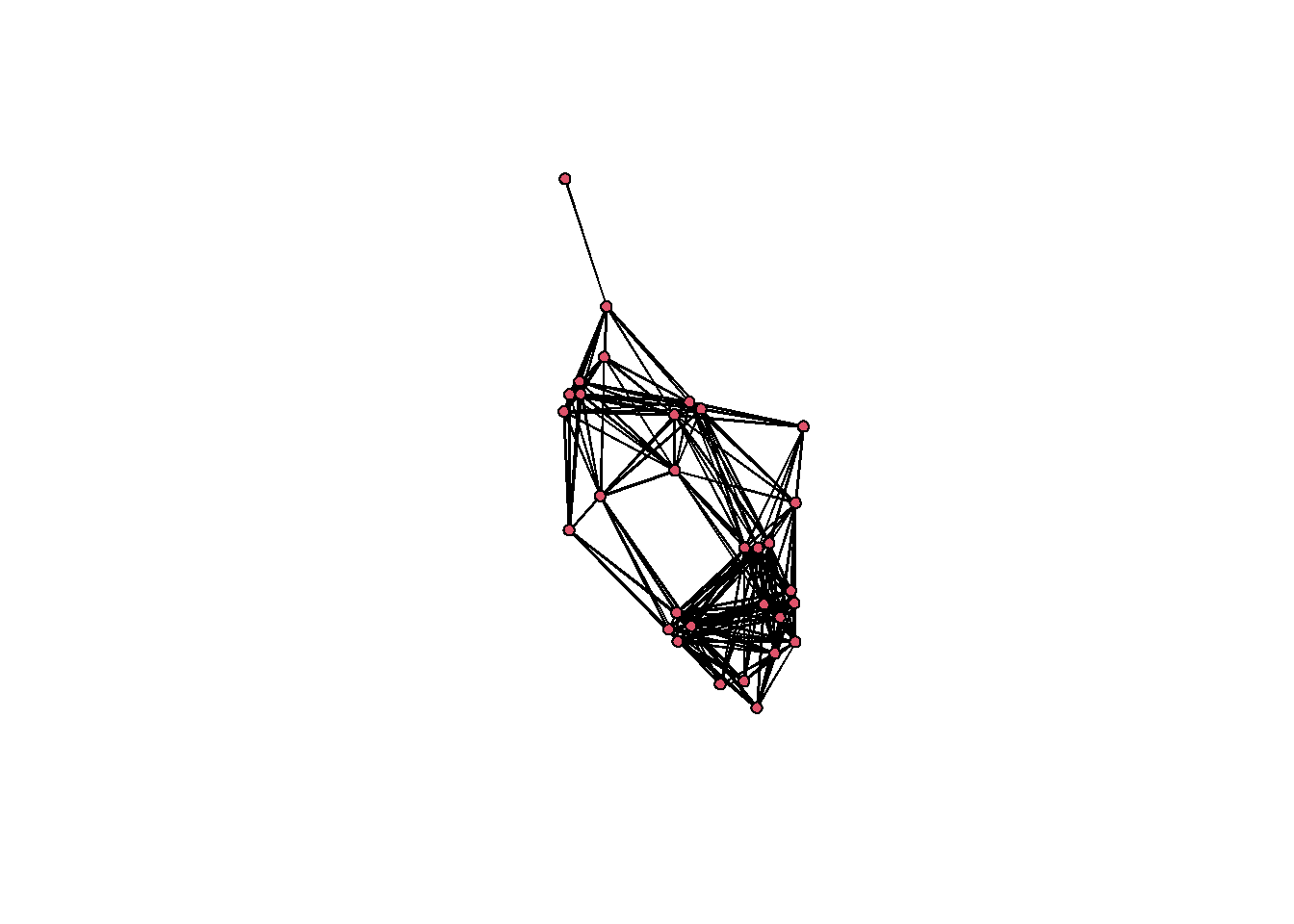
Creating Weighted Network Objects
It is also possible to use R to create weighted networks where individual edges are valued. We have found that this works reasonably well with networks of co-presence or something similar (counts of mentions in texts or monuments for example) but this does not perform well when applied to large similarity or distance matrices (because every possible link has a value, the network gets unwieldy very fast). In the latter case, we have found it is often better to just work directly with the underlying similarity/distance matrix.
If you do, however, chose to create a weighted network object from a similarity matrix it only requires a slight modification from the procedure above. In the chunk of code below, we will simply add the arguments ignore.eval = FALSE and names.eval = "weight" to let the network function know we would like weights to be retained and we would like that attribute called ‘weight’. We will apply this to the matrix of Morisita similarities defined above and then plot the result.
# create weighted network object from co-occurrence matrix by
# adding the ignore.eval=F argument
mor_wt <- network(
cibola_mor,
directed = FALSE,
ignore.eval = FALSE,
names.eval = "weight"
)
mor_wt %v% "vertex.names" <- row.names(cibola_mor)
mor_wt## Network attributes:
## vertices = 31
## directed = FALSE
## hyper = FALSE
## loops = FALSE
## multiple = FALSE
## bipartite = FALSE
## total edges= 465
## missing edges= 0
## non-missing edges= 465
##
## Vertex attribute names:
## vertex.names
##
## Edge attribute names:
## weight
The resulting network is nearly complete so it is a bit unwieldy for plotting but calculating network statistics on this weighted network can often still be useful as we will see in the exploratory analysis section.
3.2.6 Ego Networks
When we aim to understand the relational environment within which an entity is embedded, because it is relevant for our research questions or because data collection challenges dictate this focus, archaeological network research can make use of so-called ego-networks: a type of network that includes a focal node (the so-called ego), the set of nodes the ego is connected to by an edge (the so-called alters) and the edges between this set of nodes.
Extracting an ego-network from an existing igraph network object in R is very easy. Here we will extract and plot the ego-network for Apache Creek, the first site in the network files we created above. First we read in data and create a network object and then we apply the igraph::make_ego_graph function to the network object we created.
# Read in edge list file as data frame
cibola_edgelist <-
read.csv(file = "data/Cibola_edgelist.csv", header = TRUE)
# Create graph object. The data frame is converted to a matrix as
# that is required by this specific function. Since this is an
# undirected network, directed = FALSE.
cibola_net <-
igraph::graph_from_edgelist(as.matrix(cibola_edgelist),
directed = FALSE)
# Extract ego-networks
ego_nets <- make_ego_graph(cibola_net)
# Examine the first ego-network
ego_nets[[1]]## IGRAPH e89bc3c UN-- 12 59 --
## + attr: name (v/c)
## + edges from e89bc3c (vertex names):
## [1] Apache Creek --Casa Malpais Apache Creek --Coyote Creek
## [3] Casa Malpais --Coyote Creek Apache Creek --Hooper Ranch
## [5] Casa Malpais --Hooper Ranch Coyote Creek --Hooper Ranch
## [7] Apache Creek --Horse Camp Mill Casa Malpais --Horse Camp Mill
## [9] Coyote Creek --Horse Camp Mill Hooper Ranch --Horse Camp Mill
## [11] Apache Creek --Hubble Corner Casa Malpais --Hubble Corner
## [13] Coyote Creek --Hubble Corner Hooper Ranch --Hubble Corner
## [15] Horse Camp Mill--Hubble Corner Apache Creek --Mineral Creek Pueblo
## + ... omitted several edges
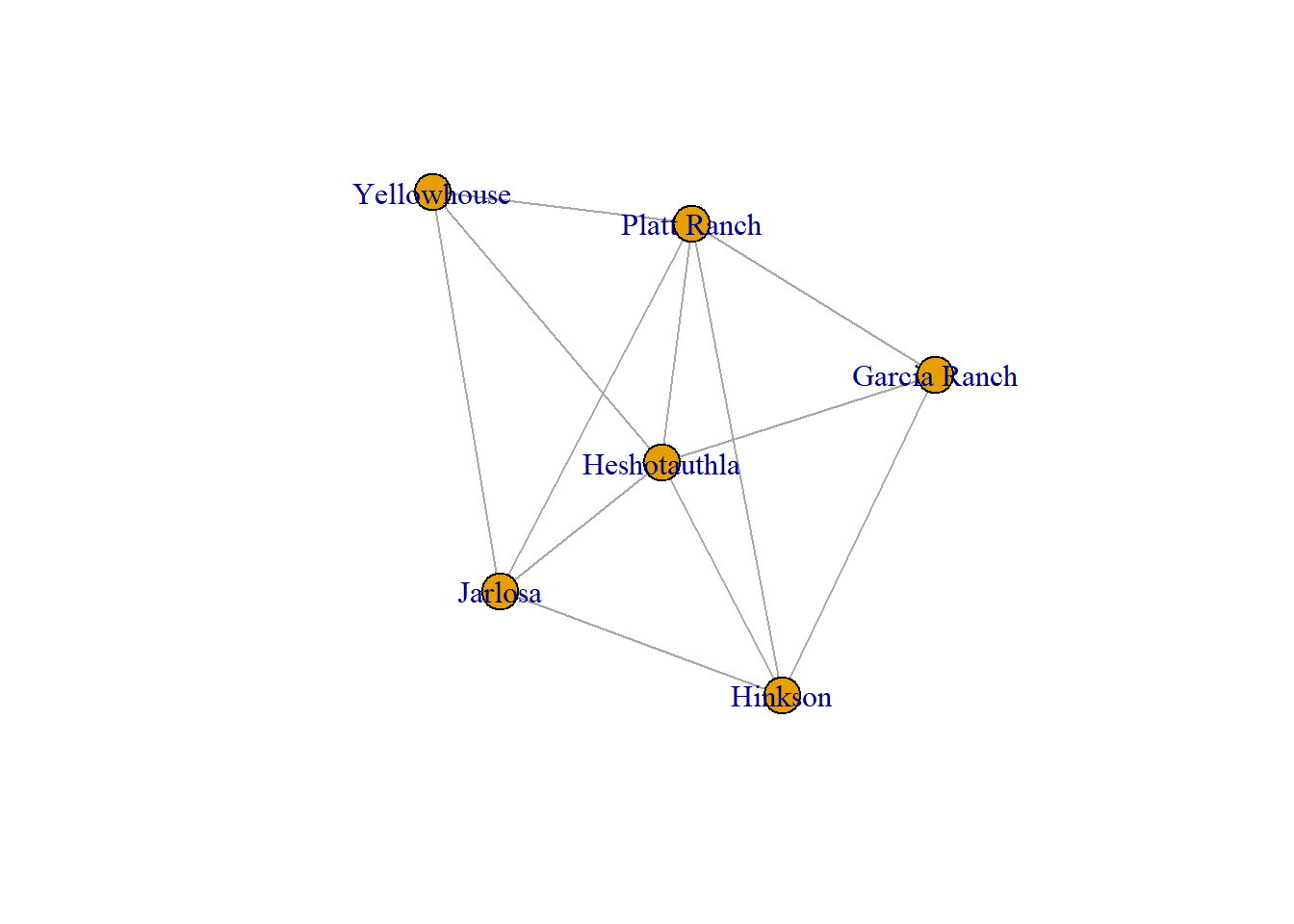
In these ego-networks, only nodes connected to the target nodes (Apache Creek in the first example and then Platt Ranch in the second) are shown and only edges among those included nodes are shown.
It is also possible to determine the size of ego-networks for an entire one-mode network using the ego_size function. The output of this function is a vector that can be further assigned as a network node attribute.
ego_size(cibola_net)## [1] 12 12 12 12 13 14 13 13 10 14 15 7 9 14 13 14 15 11 14 14 15 2 14 19 15
## [26] 12 12 11 7 63.2.7 Multilayer Network
In the simplest terms, multilayer networks are networks where a single set of nodes are connected by two or more sets of edges that each represent a different kind of relationship among the nodes. This is a relatively new area of network science in archaeological network research but we expect this will likely change in the coming years. There are now new R packages which help manage and analyze multilayer network data.
The multinet package (Rossi and Vega 2021) is designed to facilitate the analysis of multilayer networks. In order to explore some of the possibilities here we use example data and analyses included in this package. Specifically, we will look at the famous network data on Florentine families in the 14th century where connections were defined in terms of both business and marriage.
# create object with Florentine multilayer network data
florentine <- ml_florentine()
# Examine the data
florentine## ml-net[15, 2, 26, 35 (35,0)]
summary(florentine)## n m dir nc slc dens cc apl dia
## _flat_ 15 35 0 1 15 0.3333333 0.3409091 2.085714 4
## business 11 15 0 1 11 0.2727273 0.4166667 2.381818 5
## marriage 15 20 0 1 15 0.1904762 0.1914894 2.485714 5
# plot the data
plot(florentine)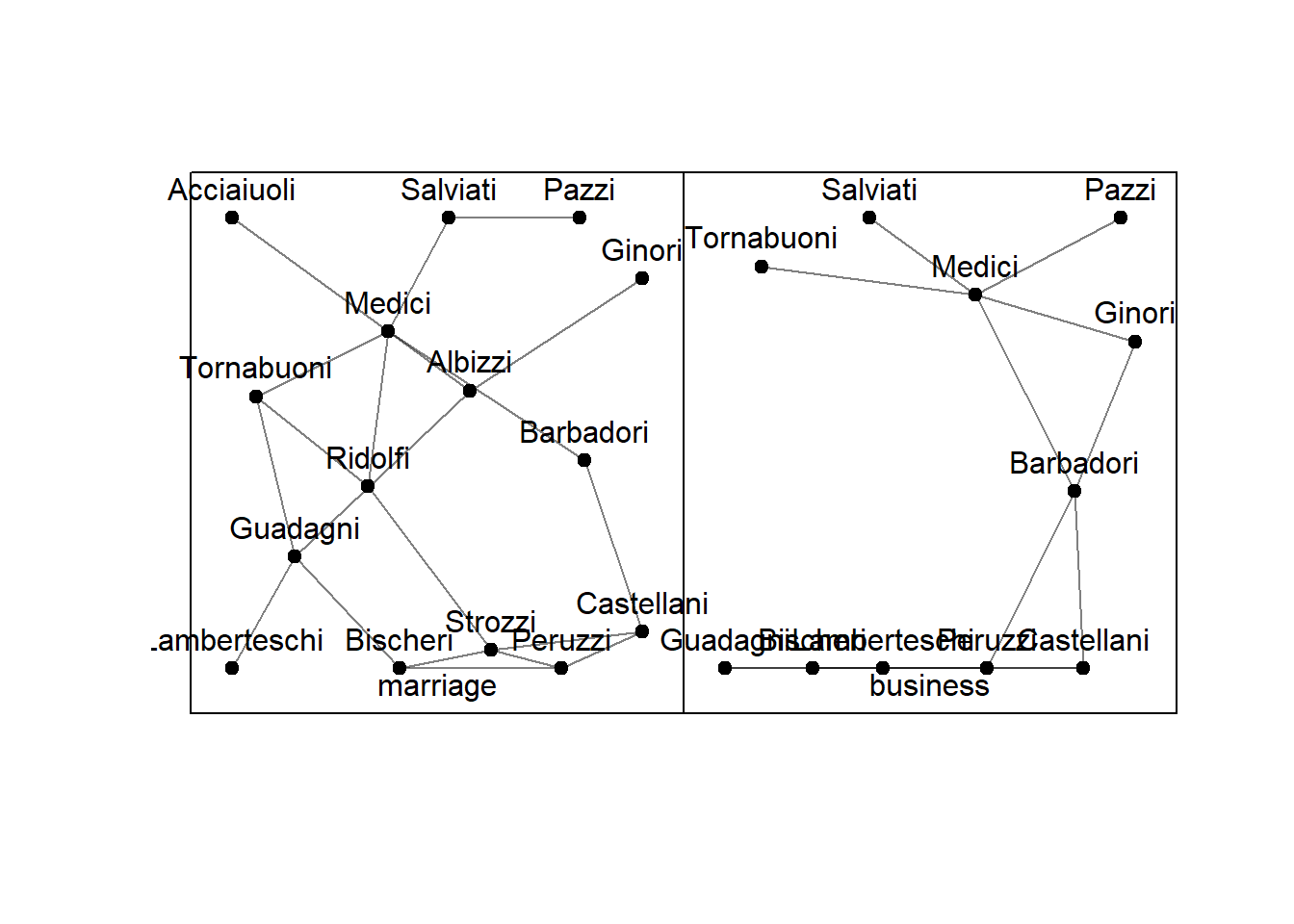
The multinet network objects are compatible with igraph and individual layers can be analyzed just like other igraph network objects. Where this multinet approach likely has greater utility is in conducting comparisons among layers or conducting analyses that take several layers into account simultaneously. A detailed exploration of this approach is beyond the scope of this document (but we provide a simple example below) and we suggest interested readers read the package information and tutorials associated with this package for more. In the example here we calculate degree across multiple layers using the degree_ml function and then run a Louvain cluster detection algorithm across all graph layers using glouvain_ml. Multilayer networks have considerable potential for archaeological data and we hope to see more research in this area in the future.
# If we want to calculate degree centrality across multiple layers of a
# multilayer network, the multinet package can help us do that directly
# and quite simply.
multinet::degree_ml(florentine)## [1] 11 4 3 1 3 5 6 3 6 3 7 2 4 6 6
# Similarly, we could apply cluster detection algorithms to all layers
# of a multilayer network simultaneously.
multinet::glouvain_ml(florentine)## actor layer cid
## 1 Medici marriage 0
## 2 Medici business 0
## 3 Tornabuoni marriage 0
## 4 Tornabuoni business 0
## 5 Ridolfi marriage 0
## 6 Acciaiuoli marriage 0
## 7 Salviati marriage 0
## 8 Salviati business 0
## 9 Pazzi marriage 0
## 10 Pazzi business 0
## 11 Albizzi marriage 1
## 12 Ginori marriage 1
## 13 Ginori business 1
## 14 Barbadori marriage 1
## 15 Barbadori business 1
## 16 Lamberteschi marriage 2
## 17 Lamberteschi business 2
## 18 Guadagni marriage 2
## 19 Guadagni business 2
## 20 Castellani marriage 2
## 21 Castellani business 2
## 22 Peruzzi marriage 2
## 23 Peruzzi business 2
## 24 Strozzi marriage 2
## 25 Bischeri marriage 2
## 26 Bischeri business 2For an archaeological example of multilevel network analysis this GitHub project by Andy Upton.
3.3 Converting Among Network Object Types
In most of the examples in this document we have been using the
igraph package but for the similarity networks we chose to
use statnet due to the convenience of functions for working
directly with similarity data. Not to worry as it is easy to convert one
format to another and preserve all of the attributes using a package
called intergraph. By way of example below we can covert
the weighted network object we created in the previous step and convert
it to a igraph object and view the attributes using the
asIgraph function. If we wanted to go the other direction
and covert a igraph object to a network object
(which is the format all of the statnet package require) we
would instead use asNetwrok.
Here is a simple example:
mor_wt_i <- asIgraph(mor_wt)
mor_wt_i## IGRAPH e8d4f6e U-W- 31 465 --
## + attr: na (v/l), vertex.names (v/c), na (e/l), weight (e/n)
## + edges from e8d4f6e:
## [1] 1-- 2 1-- 3 1-- 4 1-- 5 1-- 6 1-- 7 1-- 8 1-- 9 1--10 1--11 1--12 1--13
## [13] 1--14 1--15 1--16 1--17 1--18 1--19 1--20 1--21 1--22 1--23 1--24 1--25
## [25] 1--26 1--27 1--28 1--29 1--30 1--31 2-- 3 2-- 4 2-- 5 2-- 6 2-- 7 2-- 8
## [37] 2-- 9 2--10 2--11 2--12 2--13 2--14 2--15 2--16 2--17 2--18 2--19 2--20
## [49] 2--21 2--22 2--23 2--24 2--25 2--26 2--27 2--28 2--29 2--30 2--31 3-- 4
## [61] 3-- 5 3-- 6 3-- 7 3-- 8 3-- 9 3--10 3--11 3--12 3--13 3--14 3--15 3--16
## [73] 3--17 3--18 3--19 3--20 3--21 3--22 3--23 3--24 3--25 3--26 3--27 3--28
## [85] 3--29 3--30 3--31 4-- 5 4-- 6 4-- 7 4-- 8 4-- 9 4--10 4--11 4--12 4--13
## + ... omitted several edges
# view first 10 edge weights to show that they are retained
E(mor_wt_i)$weight[1:10]## [1] 0.4885799 0.6014729 0.9060751 0.4049019 1.0000000 0.7087214 0.7724938
## [8] 0.4521581 0.7996468 1.0000000And back in the other direction:
mor_new <- asNetwork(mor_wt_i)
mor_new## Network attributes:
## vertices = 31
## directed = FALSE
## hyper = FALSE
## loops = FALSE
## multiple = FALSE
## bipartite = FALSE
## total edges= 465
## missing edges= 0
## non-missing edges= 465
##
## Vertex attribute names:
## vertex.names
##
## Edge attribute names:
## weight
(mor_new %e% "weight")[1:10]## [1] 0.4885799 0.6014729 0.9060751 0.4049019 1.0000000 0.7087214 0.7724938
## [8] 0.4521581 0.7996468 1.0000000